6.6.1. 训练后量化(PTQ)常见问题¶
6.6.1.1. 如何理解算子约束中提及的BPU加速和CPU计算两种形式?¶
BPU加速:是指模型在板端推理时,该算子可以通过BPU硬件进行量化加速。其中,大部分算子(如conv等)是硬件直接支持的。 有些会被替换成其他算子实现加速(如gemm会被替换成conv);还有一些则依赖特定的上下文(如Reshape、Transpose需要前后均为BPU算子)才能被动量化。
CPU计算:对于模型中BPU硬件无法直接或间接加速的算子,工具链会将其放在CPU上计算,runtime预测库也会在模型推理时自动完成执行硬件的异构调度。
6.6.1.2. 如何理解模型分段的性能影响?¶
当模型在BPU算子中间存在不能加速的CPU算子时,就会被切分成不同的Subgraph(模型转换日志中会通过不同的id号进行区分),从而引入一定的性能损耗,具体包括两方面:
CPU算子性能远低于BPU算子。
CPU和BPU之间的异构调度还会引入量化、反量化算子(运行在CPU上),且因为内部计算需要遍历数据,所以其耗时会与shape大小成正比。
以上CPU算子和量化、反量化算子均可通过板端工具hrt_model_exec传入 profile_path 参数实测得到。地平线建议您尽量选择BPU算子搭建模型,以获取更好的性能表现。
6.6.1.3. 如何理解模型尾部部分BPU可加速算子运行在CPU上?¶
首先,我们需要理解以下两个概念:
J5算法工具链目前只在模型尾部支持Conv算子以int32高精度输出,其他算子都只能以int8低精度输出。
通常情况下,模型转换会在optimization阶段将Conv与其后的BN和ReLU/ReLU6融合在一起进行计算。 但由于BPU硬件本身限制,在模型尾部以int32高精度输出的Conv却并不支持算子融合。
所以如果模型以Conv+ReLU/ReLU6结尾,那么为了保证量化模型的整体精度,Conv会默认以int32高精度输出,ReLU/ReLU6则会跑在CPU上。
同理,其他尾部可加速算子运行在CPU上也都是默认精度优先的选择。不过,地平线支持在yaml文件将这些算子配置 run_on_bpu ,从而获取更好的性能表现,但会引入一定的精度损失。
6.6.1.4. 如何理解地平线的default校准方式?¶
为了减轻用户调试校准方案的工作量,地平线提供了default自动搜索策略,当前其内部逻辑如下:
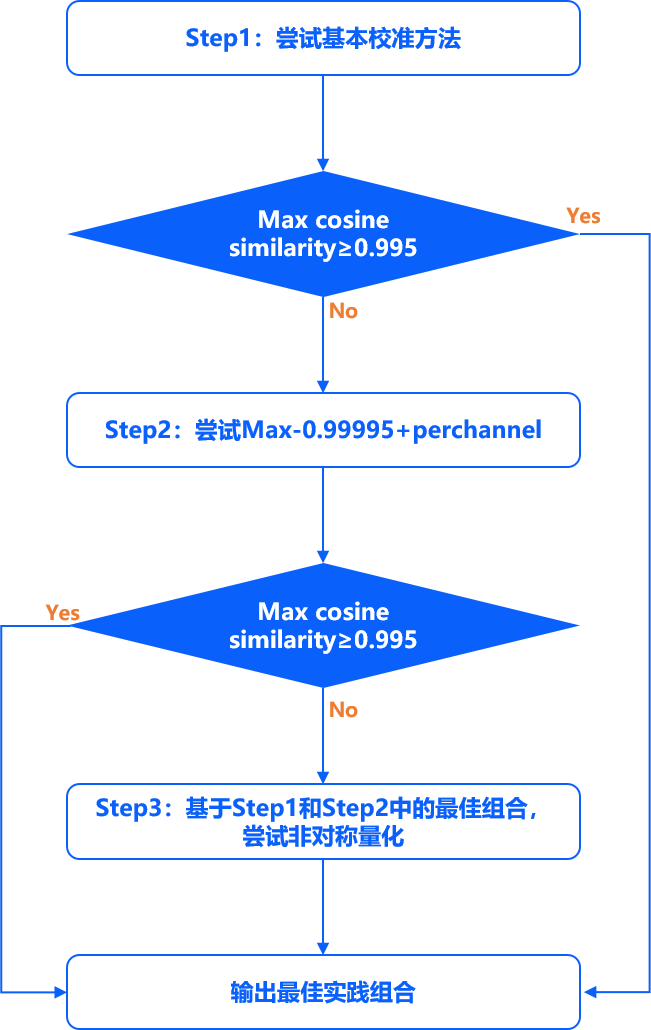
Step1:尝试Max、Max-Percentile 0.99995和KL三种校准方法,计算得到分别的余弦相似度。 如果三种方法中的最高余弦相似度小于0.995,进入Step2;反之,返回最高相似度对应的阈值组合。
Step2:尝试Max-Percentile 0.99995和perchannel量化的组合方法,如果余弦相似度仍小于0.995,进入Step3。 反之,返回最高相似度对应的阈值组合。
Step3:选取Step2中最高余弦相似度对应的方法,应用非对称量化作为第5种方法,根据余弦相似度选取5种方案中的最佳方案, 返回对应的阈值组合。
6.6.1.5. 如何理解地平线的mix校准方式?¶
为了集成不同校准方法的优势,地平线提供了mix搜索策略,当前其内部逻辑如下:
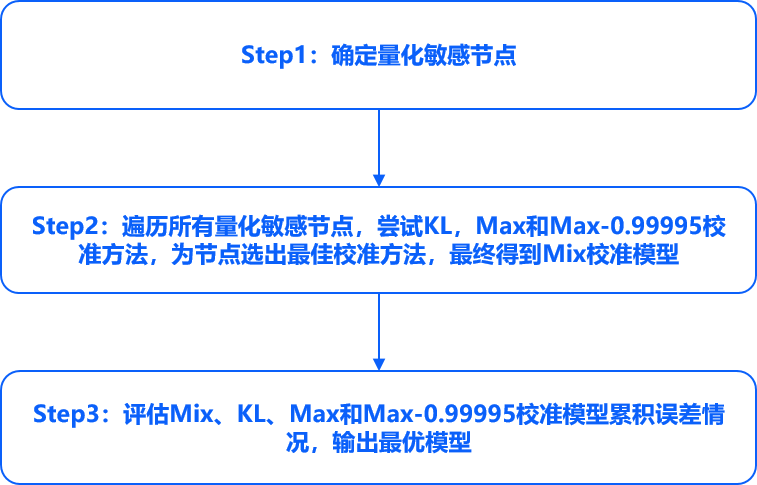
Step1:采用KL校准方法,计算当前模型中节点的量化敏感度(使用余弦相似度来衡量), 将值小于特定阈值的节点定义为量化敏感节点(对模型量化精度影响较大的节点)。
Step2:遍历所有量化敏感节点,在每一个节点上尝试Max、Max-Percentile 0.99995和KL三种校准方法, 并为该节点选出最佳的校准方法,最终得到Mix校准模型。
Step3:评估Mix、Max、Max-Percentile 0.99995和KL校准模型的累积误差情况,输出最优模型。
6.6.1.6. 如何理解yaml文件中的编译器优化等级参数?¶
在模型转换的yaml配置文件中,编译参数组提供了optimize_level参数来选择模型编译的优化等级,可选范围为 O0~O3。其中:
O0 不做任何优化,编译速度最快,适合在模型转换功能验证、调试不同校准方式时使用。
O3 优化等级最高,可以获得模型最佳性能,但编译时间也相对较长。
在 O1~O3 范围内,优化等级越高,编译优化时的搜索空间就会越大。同时,一些比较耗时的优化策略也仅会在 O2/O3 等级才会启用。
编译器的优化策略并不是算子粒度层面的,而是针对整个模型的全局优化。
6.6.1.7. 为何nv12模型hb_perf得出的输入大小和预测库不一致?¶
NV12图像格式属于YUV颜色空间中的YUV420SP格式,是摄像头可直接输出的视频格式。由于一般在实际训练时不会使用这种格式, 因此底层硬件拿到摄像头输出的数据后,会先将其转换为yuv444的格式再进行后续推理(该转换过程用户不感知,板端推理时只需依据模型转换时配置的input_type_rt准备对应类型的数据即可)。 hb_perf工具显示的是nv12数据的大小(即NxHxWx3/2),而板端hrt_model_exec model_info获取到的数据大小则是模型真实输入的数据大小(即NxHxWx3)。 且由于nv12数据已经不具有channel的概念了,板端部署时用户只需依据输入节点的H和W信息,准备对应大小的nv12数据即可。
6.6.1.8. 量化模型和上板bin模型的输入的数据排布是否一定一致?¶
onnx模型和上板bin模型的输入数据排布 不一定完全一致 。上板bin的输入数据排布与yaml配置文件中的input_layout_rt对齐,但quanti.onnx的数据排布则会因为多种因素发生改变,例如:
当模型的input type rt设置为 nv12 时,input_source默认为 pyramid , 当输入为pyramid时,量化模型quanti.onnx的输入均为NHWC。
当input type rt为 yuv444/rgb/bgr 等类型时,input_source默认为 ddr , 此时量化模型quanti.onnx的输入与原始浮点模型一致。
此外其他场景也有可能会出现***.onnx与***.bin输入数据排布不一致的情况。
因此,当您在PC端推理***.onnx时,建议使用可视化工具查看一下onnx模型的输入shape,并准备对应的数据。 当在板端推理.bin模型时,则依据转换时配置的input_layout_rt或使用工具hrt_model_exec model_info以及BPU SDK相关API(hbDNNGetInputTensorProperties())获取.bin模型的输入shape。 当您使用同一张图片推理quanti.onnx以及.bin发现输出结果差异很大时,建议您先排查输入数据排布是否正确。
6.6.1.9. 如何编译得到多batch模型?¶
根据原模型种类,我们将分为动态输入模型和非动态输入模型来讨论这个问题。
注解
input_batch参数仅在单输入且input_shape第一维为1的时候可以使用,且此参数仅在原始onnx模型本身支持多batch推理时才能生效。每份校准数据shape大小,应和
input_shape的大小保持一致。
动态输入模型:如果原模型为动态输入模型时,比如,? x3x224x224(动态输入模型必须使用input_shape参数指定模型输入信息)。
1.当配置input_shape为1x3x224x224时, 如果您想编译得到多batch的模型,可以使用 input_batch 参数,此时每份校准数据shape大小为1x3x224x224。
2.当配置input_shape的第一维为大于1的整数时,原模型本身将会认定为多batch模型,将无法使用 input_batch 参数,且需要注意每份校准数据shape大小。例如配置input_shape为4x3x224x224时, 此时每份校准数据shape大小需要为4x3x224x224。
非动态输入模型:
1.当输入的input shape[0]为1,且是单输入模型时,可以使用 input_batch 参数。每份校准数据shape大小与原模型shape保持一致。
2.当输入的input shape[0]不为1,不支持使用 input_batch 参数。
6.6.1.10. 多输入模型在转换过程中,模型输入顺序发生变化,此种情况正常么?¶
此种情况是正常现象,多输入模型在转换过程中,模型输入顺序是有可能发生变化的。 可能发生的情况如下例所示:
原始浮点模型输入顺序:input1、input2、input3。
original.onnx模型输入顺序:input1、input2、input3。
quanti.onnx模型输入顺序:input2、input1、input3。
bin模型输入顺序:input3、input2、input1。
注意
当您做精度一致性对齐时,请确保输入顺序是正确的,不然有可能会影响精度结果。
如果您想查看bin模型输入的顺序,可以使用
hb_model_info指令来查看,input_parameters info分组中列出的输入顺序,即为bin模型的输入顺序。
6.6.1.11. 如何理解PTQ模型转换过程中的主动量化和被动量化?¶
在模型成功转换成bin模型后,可能会出现发现仍然有个别op运行在CPU上的情况,但回头仔细对照工具链算子约束列表,明明该op是符合算子约束条件的,也就是理论上该算子应该成功运行在BPU上,为什么仍然是CPU计算呢?
针对此问题,您可参考 地平线官方社区文章 ,该文章对模型转换工具链中内部的量化原理与背后的逻辑进行了介绍,并针对问题提供了几种解决方法。