6.4.2. 常见算法模型示例¶
6.4.2.1. 位置路径¶
常见算法模型示例位于 horizon_model_convert_sample 路径的:
02_preq_examples/、 03_classification/、 04_detection/ 和 07_segmentation/ 文件夹中。
6.4.2.2. 如何准备数据集¶
6.4.2.2.1. 数据集下载地址¶
数据集的下载地址可参考下表:
数据集 |
下载地址 |
|---|---|
ImageNet |
|
COCO |
|
VOC |
http://host.robots.ox.ac.uk/pascal/VOC/ (需要下载2007和2012两个版本) |
Cityscapes |
|
CIFAR-10 |
6.4.2.2.2. 数据集参考结构¶
为方便您进行后续步骤,在数据集下载完成后,您需要按照如下地平线建议的结构对评测数据集进行处理。
6.4.2.2.2.1. ImageNet¶
imagenet/
├── calibration_data
│ ├── ILSVRC2012_val_00000001.JPEG
│ ├── ...
│ └── ILSVRC2012_val_00000100.JPEG
├── ILSVRC2017_val.txt
├── val
│ ├── ILSVRC2012_val_00000001.JPEG
│ ├── ...
│ └── ILSVRC2012_val_00050000.JPEG
└── val.txt
6.4.2.2.2.2. COCO¶
coco/
├── calibration_data
│ ├── COCO_val2014_000000181007.jpg
│ ├── ...
│ └── COCO_val2014_000000181739.jpg
└── coco_val2017
├── annotations
│ ├── instances_train2017.json
│ └── instances_val2017.json
└── images
├── 000000000139.jpg
├── 000000000285.jpg
├── ...
├── 000000581615.jpg
└── 000000581781.jpg
6.4.2.2.2.3. VOC¶
注意
请您注意,VOC2012目录下目前存储了VOC2007和VOC2012两份数据集,请您按照如下目录结构对评测数据集进行处理。
VOCdevkit/
└── VOC2012
├── Annotations
│ ├── 2007_000027.xml
│ ├── ...
│ └── 2012_004331.xml
├── ImageSets
│ ├── Action
│ │ ├── jumping_train.txt
│ │ ├── jumping_trainval.txt
│ │ ├── jumping_val.txt
│ │ ├── ...
│ │ ├── val.txt
│ │ ├── walking_train.txt
│ │ ├── walking_trainval.txt
│ │ └── walking_val.txt
│ ├── Layout
│ │ ├── train.txt
│ │ ├── trainval.txt
│ │ └── val.txt
│ ├── Main
│ │ ├── aeroplane_train.txt
│ │ ├── aeroplane_trainval.txt
│ │ ├── aeroplane_val.txt
│ │ ├── ...
│ │ ├── train.txt
│ │ ├── train_val.txt
│ │ ├── trainval.txt
│ │ ├── tvmonitor_train.txt
│ │ ├── tvmonitor_trainval.txt
│ │ ├── tvmonitor_val.txt
│ │ └── val.txt
│ └── Segmentation
│ ├── train.txt
│ ├── trainval.txt
│ └── val.txt
├── JPEGImages
│ ├── 2007_000027.jpg
│ ├── ...
│ └── 2012_004331.jpg
├── SegmentationClass
│ ├── 2007_000032.png
│ ├── ...
│ └── 2011_003271.png
├── SegmentationObject
│ ├── 2007_000032.png
│ ├── ...
│ └── 2011_003271.png
└── train.txt
6.4.2.2.2.4. Cityscapes¶
cityscapes/
├── cityscapes_calibration_data
│ ├── aachen_000000_000019_leftImg8bit.png
│ ├── ...
│ └── aachen_000099_000019_leftImg8bit.png
├── gtFine
│ ├── test
│ │ ├── berlin
│ │ ├── ...
│ │ └── munich
│ ├── train
│ │ ├── aachen
│ │ ├── ...
│ │ └── zurich
│ └── val
│ ├── frankfurt
│ ├── lindau
│ └── munster
├── leftImg8bit
│ ├── test
│ │ ├── berlin
│ │ ├── ...
│ │ └── munich
│ ├── train
│ │ ├── aachen
│ │ ├── ...
│ │ └── zurich
│ └── val
│ ├── frankfurt
│ ├── lindau
│ └── munster
├── license.txt
└── README
6.4.2.2.2.5. CIFAR-10¶
cifar-10/
├── batches.meta
├── cifar10_val.txt
├── data_batch_1
├── data_batch_2
├── data_batch_3
├── data_batch_4
├── data_batch_5
├── readme.html
└── test_batch
6.4.2.3. 如何准备模型¶
在使用模型转换示例包时,请您先准备好对应的浮点模型。
注解
OE包默认不携带示例对应的校准数据集和原始模型,您需要在对应的示例文件夹内执行 00_init.sh 获取当前示例所需的模型和校准数据集。
对于各原始模型的来源、修改点(如有)的准备过程,请您参考以下内容。
6.4.2.3.1. Fcos_efficientnetb0¶
注意
该模型为采用QAT方式训练出来的模型。
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对
remove_node_type参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/PreQQAT
2.md5sum码:
md5sum |
File |
|---|---|
be2fe17530bc366b038f5309199bf712 |
fcos_eff_b0.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.348(FLOAT)/0.349(INT8)
6.4.2.3.2. Fcos_efficientnetb2¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/PreQQAT
2.md5sum码:
md5sum |
File |
|---|---|
58ffc007a2ab9a053a559945fb27fac8 |
fcos_eff_b2.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.447(FLOAT)/0.447(INT8)
6.4.2.3.3. Fcos_efficientnetb3¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/PreQQAT
2.md5sum码:
md5sum |
File |
|---|---|
da37796ea8f2a4a54684a2520fdd6148 |
fcos_eff_b3.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.472(FLOAT)/0.474(INT8)
6.4.2.3.4. MobileNetv1/v2¶
1.模型来源:https://github.com/shicai/MobileNet-Caffe
2.md5sum码:
md5sum |
File |
|---|---|
3fd6889ec48bda46451d67274144e2a8 |
mobilenet.caffemodel |
8922f90f629d428fecf866e798ac7c08 |
mobilenet_deploy.prototxt |
54aab8425ea068d472e8e4015f22360c |
mobilenet_v2.caffemodel |
13101ee86ab6d217d5fd6ed46f7a4faa |
mobilenet_v2_deploy.prototxt |
3.模型精度:
MobileNetv1:0.7061(FLOAT)/0.7026(INT8)
MobileNetv2:0.7165(FLOAT)/0.7120(INT8)
6.4.2.3.5. GoogleNet¶
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/GoogleNet
2.md5sum码:
md5sum |
File |
|---|---|
f107ae6806ea1016afbc718210b7a617 |
googlenet.onnx |
3.模型精度:0.7001(FLOAT)/0.6989(INT8)
6.4.2.3.6. ResNet18¶
1.模型来源:https://github.com/HolmesShuan/ResNet-18-Caffemodel-on-ImageNet
2.md5sum码:
md5sum |
File |
|---|---|
0904d601fc930d4f0c62a2a95b3c3b93 |
resnet18.caffemodel |
ee8ac82cd693a0fe55af42cca3fc52e5 |
resnet18_deploy.prototxt |
3.模型精度:0.6837(FLOAT)/0.6829(INT8)
6.4.2.3.7. EfficientNet_Lite0/1/2/3/4¶
注意
为了快速运行示例,避免使用第三方工具带来的风险,强烈推荐您直接使用地平线模型发布物 model_zoo/mapper/ 路径下准备好的ONNX浮点模型。 如果您有兴趣复现tflite2onnx的模型转换过程,也可以尝试使用以下三方工具。但地平线无法保证第三方工具的质量和转换成功率。
1.模型来源:可从 https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet/lite 获取tar包。
2.地平线模型发布物中转换后的ONNX模型md5sum码:
md5sum |
File |
|---|---|
001a329bd367fbec22b415c7a33d7bdb |
efficientnet_lite0_fp32.onnx |
1205e95aea66650c71292bde236d55a9 |
efficientnet_lite1_fp32.onnx |
474741c15494b79a89fe51d89e0c43c7 |
efficientnet_lite2_fp32.onnx |
550455b41848d333f8359279c89a6bae |
efficientnet_lite3_fp32.onnx |
bde7fe57eadb4a30ef76f68da622dcd5 |
efficientnet_lite4_fp32.onnx |
3.下载后可从tar包中得到 .tflite 文件,然后可通过tflite2onnx工具 (https://pypi.org/project/tflite2onnx/) 将tflite转换为ONNX模型。
不同版本的tflite2onnx转换出来的layout会不一样,若转换出来的ONNX模型的输入layout是NHWC排布,则build时,
EfficientNet_Lite0/1/2/3/4的 input_layout_train 均应该选择 NHWC。
4.模型精度:
EfficientNet_Lite0:0.7490(FLOAT)/0.7469(INT8)
EfficientNet_Lite1:0.7648(FLOAT)/0.7624(INT8)
EfficientNet_Lite2:0.7738(FLOAT)/0.7715(INT8)
EfficientNet_Lite3:0.7922(FLOAT)/0.7902(INT8)
EfficientNet_Lite4:0.8069(FLOAT)/0.8058(INT8)
6.4.2.3.8. Vargconvnet¶
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/VargConvNet
2.md5sum码:
md5sum |
File |
|---|---|
e21b8db17916f9046253bbe0bb8de3ef |
vargconvnet.onnx |
3.模型精度:0.7790(FLOAT)/0.7785(INT8)
6.4.2.3.9. Efficientnasnet_m¶
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/EfficientnasNet
2.md5sum码:
md5sum |
File |
|---|---|
fc36c052c6f034c0b64a6197b91b0c62 |
efficientnasnet-m.onnx |
3.模型精度:0.7973(FLOAT)/0.7916(INT8)
6.4.2.3.10. Efficientnasnet_s¶
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/EfficientnasNet
2.md5sum码:
md5sum |
File |
|---|---|
e2744bd748f4265f4488676835a6ca24 |
efficientnasnet-s.onnx |
3.模型精度:0.7578(FLOAT)/0.7518(INT8)
6.4.2.3.11. YOLOv2_Darknet19¶
注意
为了快速运行示例,避免使用第三方工具带来的风险,强烈推荐您直接使用地平线模型发布物 model_zoo/mapper/ 路径下准备好的Caffe浮点模型。 如果您有兴趣复现darknet2caffe的模型转换过程,也可以尝试使用以下三方工具。但地平线无法保证三方工具的质量和转换成功率。
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.YOLOv2_Darknet19模型需要首先从YOLO官网(https://pjreddie.com/darknet/yolo/),下载YOLOv2 608x608的.cfg和.weight文件 并使用darknet2caffe (https://github.com/xingyanan/darknet2caffe) 转换工具将其转换为caffe model。
注解
该转换工具(darknet2caffe)是一个简化版本,使用时,需要修改该工具生成的.prototxt文件,将其中的 'Reshape' 层修改成 'Passthrough' 层,
Passthrough 层具体修改后的参数请见提供的yolov2.prototxt例子,并在输出节点增加一个NCHW2NHWC的Permute操作。
2.md5sum码:
md5sum |
File |
|---|---|
7aa7a6764401cebf58e73e72fcbd2a45 |
yolov2.caffemodel |
72e9a51c1e284e4b66e69f72ca9214c8 |
yolov2_transposed.prototxt |
3.模型精度:
[IoU=0.50:0.95]: 0.276(FLOAT)/0.273(INT8)
6.4.2.3.12. YOLOv3_Darknet53¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.YOLOv3_Darknet53模型获取:
URL: https://github.com/ChenYingpeng/caffe-yolov3/ ,caffemodel可以在该github的README.md提供的百度云下载路径中下载,并在输出节点增加一个NCHW2NHWC的Permute操作。
2.md5sum码:
md5sum |
File |
|---|---|
935af6e1530af5c0017b3674adce95e9 |
yolov3_transposed.prototxt |
9a0f09c850656913ec27a6da06d9f9cc |
yolov3.caffemodel |
3.模型精度:
[IoU=0.50:0.95]:0.333(FLOAT)/0.335(INT8)
6.4.2.3.13. YOLOv5x¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.YOLOv5x模型:可以从URL: https://github.com/ultralytics/yolov5/releases/tag/v2.0 中下载相应的pt文件。
注意
在clone代码时,请确认您使用的Tags是 v2.0,否则将导致转换失败。
2.md5sum码:
md5sum |
File |
|---|---|
2e296b5e31bf1e1b6b8ea4bf36153ea5 |
yolov5l.pt |
16150e35f707a2f07e7528b89c032308 |
yolov5m.pt |
42c681cf466c549ff5ecfe86bcc491a0 |
yolov5s.pt |
069a6baa2a741dec8a2d44a9083b6d6e |
yolov5x.pt |
为了更好地适配后处理代码,我们在ONNX模型导出前对Github代码做了如下修改(代码参见:https://github.com/ultralytics/yolov5/blob/v2.0/models/yolo.py):
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x[i] = x[i].permute(0, 2, 3, 1).contiguous()
注解
去除了每个输出分支尾部从4维到5维的reshape(即不将channel从255拆分成3x85),然后将layout从NHWC转换成NCHW再输出。
以下左图为修改前的模型某一输出节点的可视化图,右图则为修改后的对应输出节点可视化图。
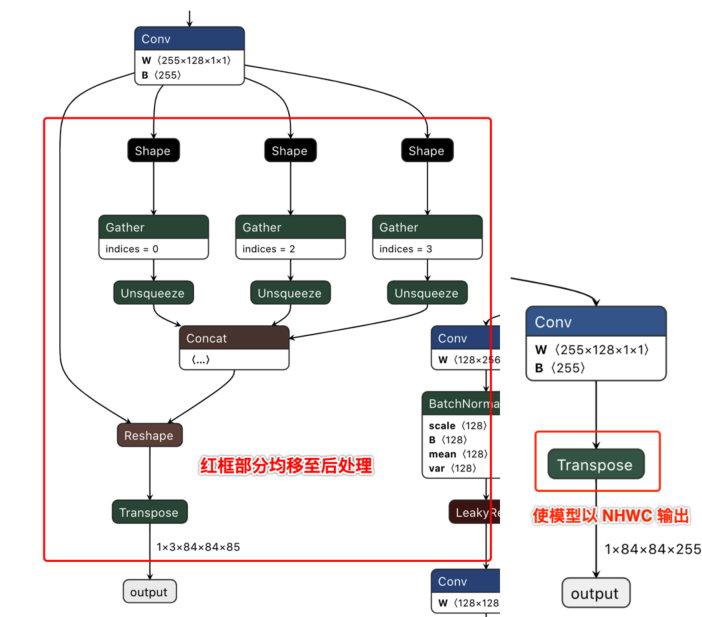
下载完成后通过脚本 https://github.com/ultralytics/yolov5/blob/v2.0/models/export.py 进行pt文件到ONNX文件的转换。
注意
在使用export.py脚本时,请注意:
由于地平线算法工具链支持的ONNX opset版本为 10 和 11,请将
torch.onnx.export的opset_version参数根据您要使用的版本进行修改。将
torch.onnx.export部分的默认输入名称参数由'images'改为'data',与模型转换示例包的YOLOv5x示例脚本保持一致。将
parser.add_argument部分中默认的数据输入尺寸640x640改为模型转换示例包YOLOv5x示例中的672x672。
3.模型精度:
[IoU=0.50:0.95]:0.480(FLOAT)/0.466(INT8)
6.4.2.3.14. SSD_MobileNetv1¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.SSD_MobileNetv1模型:可以从URL: https://github.com/chuanqi305/MobileNet-SSD 获得Caffe模型。
2.md5sum码:
md5sum |
File |
|---|---|
bbcb3b6a0afe1ec89e1288096b5b8c66 |
mobilenet_iter_73000.caffemodel |
3c230e4415195a50c6248be80c49882d |
MobileNetSSD_deploy.prototxt |
3.模型精度(mAP):0.7342(FLOAT)/0.7275(INT8)
6.4.2.3.15. Efficientdetd0¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/EfficientDet
2.md5sum码:
md5sum |
File |
|---|---|
ec4129c4b300cd04f1e8f71e0fe54ca5 |
efficientdet_nhwc.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.324(FLOAT)/0.315(INT8)
6.4.2.3.16. CenterNet_Resnet101¶
注意
为保证板端性能达到最优:
我们将maxpool和sigmoid节点放到模型中,并指定编译为BPU节点,用于减少后处理过程中的计算量。
在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/Centernet
2.md5sum码:
md5sum |
File |
|---|---|
db195ff784792f475e573c5126401d2a |
centernet_resnet101_coco_modify.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.342(FLOAT)/0.335(INT8)
6.4.2.3.17. Fcos_efficientnetb0¶
注意
该模型为采用PTQ方式训练出来的模型。
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/blob/master/Fcos_Efficientnetb0
2.md5sum码:
md5sum |
File |
|---|---|
9f9a1fe8508e2bd068e70146eb559b4f |
fcos_efficientnetb0.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.358(FLOAT)/0.351(INT8)
6.4.2.3.18. Yolov4¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/YoloV4
2.md5sum码:
md5sum |
File |
|---|---|
aaa3c3e5e4c4c1d4830b6501b1720e4d |
yolov4_efficientnetb0.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.351(FLOAT)/0.335(INT8)
6.4.2.3.19. YOLOv3_VargDarknet¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.YOLOv3_VargDarknet模型获取:
URL: https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/Yolov3_VargDarknet ,可以在该github的README.md提供的百度云下载路径中下载。
2.md5sum码:
md5sum |
File |
|---|---|
fd4e46bc7c9798b51778d3aa09c5053a |
yolov3_vargdarknet53.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.335(FLOAT)/0.327(INT8)
6.4.2.3.20. Fcos_resnet50¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/Fcos_Resnet50
2.md5sum码:
md5sum |
File |
|---|---|
0218942777615fac2f54cefdac4fbfa7 |
fcos_resnet50.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.426(FLOAT)/0.424(INT8)
6.4.2.3.21. Fcos_resnext101¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/Fcos_Resnext101
2.md5sum码:
md5sum |
File |
|---|---|
4b80efd22448021721ac5a860909c59f |
fcos_resnext101.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.453(FLOAT)/0.450(INT8)
6.4.2.3.22. Unet_mobilenet¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Dequantize节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/MobilenetUnet
2.md5sum码:
md5sum |
File |
|---|---|
21c6c645ebca92befbebc8c39d385c1e |
tf_unet_trained.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.6411(FLOAT)/0.6379(INT8)
6.4.2.3.23. DeeplabV3plus_efficientnetb0¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Reshape和Cast节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/DeeplabV3Plus
2.md5sum码:
md5sum |
File |
|---|---|
cf3a683f31b4b0ebe090647729f869d9 |
deeplabv3plus_efficientnetb0.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.7630(FLOAT)/0.7568(INT8)
6.4.2.3.24. Fastscnn_efficientnetb0¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Reshape和Cast节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/FastSCNN
2.md5sum码:
md5sum |
File |
|---|---|
c1ace8f08a9c7b9c91509fa68327d0c8 |
fastscnn_efficientnetb0.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.6997(FLOAT)/0.6928(INT8)
6.4.2.3.25. Deeplabv3plus_dilation1248¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Transpose节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/DeeplabV3Plus
2.md5sum码:
md5sum |
File |
|---|---|
ad002e572cbb49e1e99d893aac69f3e3 |
deeplabv3_cityscapes_dila1248_permute.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.7462(FLOAT)/0.7452(INT8)
6.4.2.3.26. Deeplabv3plus_efficientnetm1¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Reshape、Cast和Transpose节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/DeeplabV3Plus
2.md5sum码:
md5sum |
File |
|---|---|
0a1dfd01e173c68630d9e8dc1a6036fe |
deeplabv3plus_efficientnetm1.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.7794(FLOAT)/0.7740(INT8)
6.4.2.3.27. Deeplabv3plus_efficientnetm2¶
注意
为保证板端性能达到最优,在编译bin模型的yaml文件中我们对 remove_node_type 参数进行了配置,将bin模型中的Reshape、Cast和Transpose节点做了删除的操作。
1.模型来源:https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master/DeeplabV3Plus
2.md5sum码:
md5sum |
File |
|---|---|
c11a2673c4b3cf6e5d7bf1a051925d38 |
deeplabv3plus_efficientnetm2.onnx |
3.模型精度:
[IoU=0.50:0.95]:0.7882(FLOAT)/0.7856(INT8)
6.4.2.4. 算法模型示例的使用演示¶
本小节以GoogleNet模型为例,使用算法模型示例包中 03_classification/02_googlenet/mapper/ 路径下脚本
分步骤演示浮点模型到定点模型转换的过程。
6.4.2.4.1. 进入Docker容器¶
首先,根据 Docker容器部署 一节内容完成Docker环境的安装和配置并进入docker容器。
6.4.2.4.2. 下载原始模型及校准数据集¶
在 03_classification/02_googlenet/mapper/ 文件夹内执行 00_init.sh 获取当前示例所需的模型和校准数据集。
# 1. 进入示例脚本放置的文件夹
cd ddk/samples/ai_toolchain/horizon_model_convert_sample/03_classification/02_googlenet/mapper
# 2. 执行脚本下载原始模型及校准数据集
sh 00_init.sh
6.4.2.4.3. 验证模型是否能够执行¶
1.如下所示,运行脚本:
# 执行模型检查
sh 01_check.sh
2.模型检查输出:
上述脚本使用 hb_mapper checker 工具验证模型是否被地平线计算平台支持。同时也会输出一个OP列表,表示每个OP会CPU还是BPU上执行。
如下所示:
======================================================================
Node ON Subgraph Type
-----------------------------------------------------------------------
Conv_0 BPU id(0) HzSQuantizedConv
MaxPool_3 BPU id(0) HzQuantizedMaxPool
Conv_4 BPU id(0) HzSQuantizedConv
Conv_7 BPU id(0) HzSQuantizedConv
MaxPool_10 BPU id(0) HzQuantizedMaxPool
Conv_11 BPU id(0) HzSQuantizedConv
Conv_14 BPU id(0) HzSQuantizedConv
Conv_17 BPU id(0) HzSQuantizedConv
Conv_20 BPU id(0) HzSQuantizedConv
Conv_23 BPU id(0) HzSQuantizedConv
MaxPool_26 BPU id(0) HzQuantizedMaxPool
Conv_27 BPU id(0) HzSQuantizedConv
Concat_30 BPU id(0) Concat
Conv_31 BPU id(0) HzSQuantizedConv
Conv_34 BPU id(0) HzSQuantizedConv
Conv_37 BPU id(0) HzSQuantizedConv
Conv_40 BPU id(0) HzSQuantizedConv
Conv_43 BPU id(0) HzSQuantizedConv
MaxPool_46 BPU id(0) HzQuantizedMaxPool
Conv_47 BPU id(0) HzSQuantizedConv
Concat_50 BPU id(0) Concat
MaxPool_51 BPU id(0) HzQuantizedMaxPool
Conv_52 BPU id(0) HzSQuantizedConv
Conv_55 BPU id(0) HzSQuantizedConv
Conv_58 BPU id(0) HzSQuantizedConv
Conv_61 BPU id(0) HzSQuantizedConv
Conv_64 BPU id(0) HzSQuantizedConv
MaxPool_67 BPU id(0) HzQuantizedMaxPool
Conv_68 BPU id(0) HzSQuantizedConv
Concat_71 BPU id(0) Concat
Conv_72 BPU id(0) HzSQuantizedConv
Conv_75 BPU id(0) HzSQuantizedConv
Conv_78 BPU id(0) HzSQuantizedConv
Conv_81 BPU id(0) HzSQuantizedConv
Conv_84 BPU id(0) HzSQuantizedConv
MaxPool_87 BPU id(0) HzQuantizedMaxPool
Conv_88 BPU id(0) HzSQuantizedConv
Concat_91 BPU id(0) Concat
Conv_92 BPU id(0) HzSQuantizedConv
Conv_95 BPU id(0) HzSQuantizedConv
Conv_98 BPU id(0) HzSQuantizedConv
Conv_101 BPU id(0) HzSQuantizedConv
Conv_104 BPU id(0) HzSQuantizedConv
MaxPool_107 BPU id(0) HzQuantizedMaxPool
Conv_108 BPU id(0) HzSQuantizedConv
Concat_111 BPU id(0) Concat
Conv_112 BPU id(0) HzSQuantizedConv
Conv_115 BPU id(0) HzSQuantizedConv
Conv_118 BPU id(0) HzSQuantizedConv
Conv_121 BPU id(0) HzSQuantizedConv
Conv_124 BPU id(0) HzSQuantizedConv
MaxPool_127 BPU id(0) HzQuantizedMaxPool
Conv_128 BPU id(0) HzSQuantizedConv
Concat_131 BPU id(0) Concat
Conv_132 BPU id(0) HzSQuantizedConv
Conv_135 BPU id(0) HzSQuantizedConv
Conv_138 BPU id(0) HzSQuantizedConv
Conv_141 BPU id(0) HzSQuantizedConv
Conv_144 BPU id(0) HzSQuantizedConv
MaxPool_147 BPU id(0) HzQuantizedMaxPool
Conv_148 BPU id(0) HzSQuantizedConv
Concat_151 BPU id(0) Concat
MaxPool_152 BPU id(0) HzQuantizedMaxPool
Conv_153 BPU id(0) HzSQuantizedConv
Conv_156 BPU id(0) HzSQuantizedConv
Conv_159 BPU id(0) HzSQuantizedConv
Conv_162 BPU id(0) HzSQuantizedConv
Conv_165 BPU id(0) HzSQuantizedConv
MaxPool_168 BPU id(0) HzQuantizedMaxPool
Conv_169 BPU id(0) HzSQuantizedConv
Concat_172 BPU id(0) Concat
Conv_173 BPU id(0) HzSQuantizedConv
Conv_176 BPU id(0) HzSQuantizedConv
Conv_179 BPU id(0) HzSQuantizedConv
Conv_182 BPU id(0) HzSQuantizedConv
Conv_185 BPU id(0) HzSQuantizedConv
MaxPool_188 BPU id(0) HzQuantizedMaxPool
Conv_189 BPU id(0) HzSQuantizedConv
Concat_192 BPU id(0) Concat
GlobalAveragePool_193 BPU id(0) HzSQuantizedGlobalAveragePool
Gemm_195 BPU id(0) HzSQuantizedConv
Gemm_195_reshape_output CPU -- Reshape
6.4.2.4.4. 准备校准用的数据集¶
在同一路径下继续执行 02_preprocess.sh 脚本,如下所示:
# 将 01_common/data/imagenet/calibration_data中的图片
# 转换到: ./calibration_data_rgb_f32
sh 02_preprocess.sh
注解
我们从ImageNet数据集抽取了100张图作为校准数据集,在校准前,我们对数据进行了预处理: short size resize/crop size/NHWC to NCHW/转为rgb。
hb_mapper工具会从转换得到二进制数据中读取数据,预处理过的二进制数据文件格式为:c-order的矩阵存储。每个矩阵值的数据类型为uint8。
6.4.2.4.5. build异构模型¶
在同一路径下继续执行 03_build.sh 脚本,如下所示:
sh 03_build.sh
注解
上述脚本使用 hb_mapper 工具转换模型,最需要关注的是转换的配置文件,
请参考 模型编译命令(hb_mapper makertbin) 章节的内容。
上述脚本的输出如下所示:
ls model_output | cat
cache.json
googlenet_224x224_nv12.bin
googlenet_224x224_nv12_calibrated_model.onnx
googlenet_224x224_nv12_optimized_float_model.onnx
googlenet_224x224_nv12_original_float_model.onnx
googlenet_224x224_nv12_quantized_model.onnx
torch-jit-export_subgraph_0.html
torch-jit-export_subgraph_0.json
注解
您暂时只需要关心 googlenet_224x224_nv12.bin 文件。
6.4.2.4.6. 单张图片推理¶
执行 04_inference.sh 脚本进行单张图片的推理过程,如下所示:
sh 04_inference.sh
注解
因为图片推理过程时,需要对图片进行 前处理,对模型数据进行 后处理,所以我们提供了一个示例Python脚本。具体请参考
sh 04_inference.sh。此脚本只是对单张图片进行推理,验证单张图片的推理结果是否符合预期,如果想做精度测评,可以参考
05_evaluate.sh脚本。
6.4.2.4.7. 精度测试¶
继续执行 05_evaluate.sh 脚本进行精度评测,如下所示:
export PARALLEL_PROCESS_NUM=${parallel_process_num}
sh 05_evaluate.sh
注解
因为精度评测时,需要对图片进行 前处理,对模型数据进行 后处理,所以我们提供了一个示例Python脚本。具体请参考
sh 05_evaluate.sh。为了加快评测速度,可以通过
-p选项适当调整并发进程数,但需要注意内存的占用情况。当-p选项值不填或者设置为0时,CPU环境中的定点模型将按照10个进程数处理,其他场景均按1个进程数处理。
6.4.2.5. 常见问题¶
6.4.2.5.1. 如何对齐开源框架训练得到的ONNX原始浮点模型与使用 hb_mapper makertbin 工具得到的***_original_float_model.onnx的结果?¶
注解
原始浮点模型与转换得到ONNX浮点模型的差异由工具链产品保障,这种验证不是必须的标准流程。
1.明确两者的概念
首先明确两个模型的概念。
前者是指开发者使用开源框架(如:TensorFlow、PyTorch、MXNet等)训练出浮点模型后,转成ONNX格式的原始浮点模型。
而后者是指使用算法工具链浮点定点模型转换方案的 hb_mapper makertbin 工具,
或运行地平线模型转换示例包(即:horizon_model_convert_sample发布物)中03_classification/${modelname}/mapper/03_build.sh将前者
转换成*_original_float_model.onnx中间格式模型,其中的*代表的是具体模型名称(如:MobileNetv1或GoogleNet等)。
2.明确两者的差异
*_original_float_model.onnx模型计算精度与转换输入的原始浮点模型是一模一样的, 有个重要的变化就是为了适配地平线平台添加了一些数据预处理计算。 一般情况下,您不需要使用这个模型,在转换结果出现异常时,如果能把这个模型提供给地平线的技术支持,将有助于帮助您快速解决问题。
3.编写脚本对齐两者结果
注解
下面以地平线模型转换示例包(即:horizon_model_convert_sample发布物)中的googlenet模型为例进行说明。
开发者需要自行编写脚本对齐两者的结果。在编写脚本时,需要注意以下几点。
注意
开发者自编写脚本中的图片数据处理逻辑应当与工具链示例包各模型的mapper/preprocess.py图片数据预处理脚本中的逻辑一致, 以避免由图片数据预处理方法不一致造成的结果差异。 如遇模型示例包版本不同造成的代码逻辑差异,请参见您获取到的示例包版本的图片数据预处理脚本,或咨询地平线技术团队。 各预处理transformer方法参见以下代码块:
import sys
sys.path.append("../../../01_common/python/data/")
from transformer import *
from dataloader import *
# 图片校正transformer
def calibration_transformers():
"""
step:
1、short size resize to 256
2、crop size 224 * 224 from center
3、NHWC to NCHW
4、bgr to rgb
"""
transformers = [
ShortSideResizeTransformer(short_size=256),
CenterCropTransformer(crop_size=224),
HWC2CHWTransformer(),
BGR2RGBTransformer()
]
return transformers
# 图片推理transformer
def infer_transformers(input_layout="NHWC"):
"""
step:
1、PIL resize to 256
2、crop size 224*224 from PIL center
3、bgr to nv12
4、nv12 to yuv444
:param input_layout: input layout
"""
transformers = [
PILResizeTransformer(size=256),
PILCenterCropTransformer(size=224),
BGR2NV12Transformer(data_format="HWC"),
NV12ToYUV444Transformer((224, 224)),
yuv444_output_layout=input_layout[1:]),
]
return transformers
开发者可以参照以下代码块对齐图片数据预处理逻辑:
def ShortSideResizeTransformer(data, short_size):
image = data
height, width, _ = image.shape
if height < width:
off = width / height
image = cv2.resize(image,
(int(short_size * off), short_size))
else:
off = height / width
image = cv2.resize(image,
(short_size, int(short_size * off)))
data = image
data = data.astype(np.float32)
return data
def CenterCropTransformer(data, crop_size):
image = data
resize_height, resize_width, _ = image.shape
resize_up = resize_height // 2 - crop_size // 2
resize_left = resize_width // 2 - crop_size // 2
data = image[resize_up:resize_up +
crop_size, resize_left:resize_left +
crop_size, :]
data = data.astype(np.float32)
return data
def preprocess(data):
data = ShortSideResizeTransformer(data, short_size=256) # ShortSideResize
data = CenterCropTransformer(data, crop_size=224) # CenterCrop
data = np.transpose(data, (2, 0, 1)) # HWC2CHW
data = data * 255 # (0, 1) --> (0, 255)
注意
如下图所示,googlenet_224x224_nv12_original_float_model.onnx模型比原始浮点onnx模型多了HzPreprocess算子用来实现
googlenet_config.yaml文件中的 data_mean_and_scale。
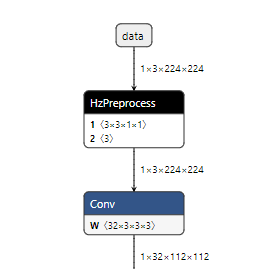
因此,开发者需要根据googlenet_config.yaml中的 mean_value 和 scale_value 参数实现数据归一化。
参见以下代码块:
# Normalize
data = data.astype(np.float32)
mean = np.array([127.5, 127.5, 127.5])
scale = np.array([0.0078431, 0.0078431, 0.0078431])
norm_data = np.zeros(data.shape).astype(np.float32)
for i in range(data.shape[0]):
norm_data[i,:,:] = (data[i,:,:] - mean[i]) * scale[i]
norm_data = norm_data.reshape(1, 3, 224, 224).astype(np.float32)
注意
由于示例包中各模型 mapper/04_inference.sh 脚本默认执行的是定点模型推理,因此在验证浮点模型结果时,
需要将定点模型推理改为浮点模型推理。执行命令 sh 04_inference.sh origin 即可执行浮点模型推理。
代码逻辑可能由于发布物版本不同略有差异,可参见 03_classification/02_googlenet/mapper/04_inference.sh 脚本中的注释内容。
实现上述步骤后即可对齐原始浮点模型与googlenet_224x224_nv12_original_float_model.onnx模型的结果了。
6.4.2.5.2. 复现的精度为什么与文档中提供的指标有细微差异?¶
出现此种现象的原因可能有以下两点:
在不同的服务器环境下,计算方式上可能会有细小的区别,就会导致不同的服务器环境中编译出来的定点onnx模型的精度与文档的记录值有细微数据波动。
用户侧使用的第三方库如 opencv、numpy等库的版本不同,导致图片经过前处理后的得到的结果不同,这种情况也会导致精度复现时与文档中的记录值有细微数据波动。
出现这种情况,您可以不用过于担心,文档中提供的记录指标仅作为参考,您在复现时的精度与文档中的记录值有细微差异是正常现象,可以正常跑通精度即可。
6.4.2.5.3. 定点模型精度为何与ai_benchmark示例中的bin文件上板精度无法对齐?¶
在标准交付中,我们在添加示例的时候,定点模型精度和ai_benchmark示例中的bin文件上板精度是已经做了对齐处理的。
如果您发现定点模型精度与ai_benchmark示例中的bin文件上板精度无法对齐的情况,建议您优先检查模型输入是否一致。 由于执行定点模型评估脚本时,使用到的是图片类型的数据集;而上板使用到的 bin 模型,需要使用hb_eval_preprocess工具转换后的二进制数据集。 基于此点,如果您在上板时使用的数据集并非通过上述方式生成的, 我们建议您先在运行定点模型的精度的相同服务器上, 使用我们的数据预处理工具(即hb_eval_preprocess工具)重新生成上板需要的数据集,重跑上板精度,以保证模型输入一致。
注意
注意,在使用hb_eval_preprocess工具生成数据集和运行定点模型精度时,两者使用的环境需要保证一致。