8.2. 高效模型设计指导¶
8.2.1. 概述¶
为了应对更高等级的自动驾驶场景,地平线于2021年推出了128Tops高算力的征程5计算平台(以下简称J5),专门为大模型而设计。 作为一款作为一款ASIC,BPU包含多种专用硬件计算单元,各硬件单元在设计时为了更高的性能可能牺牲了部分灵活性,因此需要各位开发者们在了解BPU的特性后,针对性地对模型做出一些更贴合硬件特点的优化,以尽可能发挥出BPU的计算优势。 下文将具体阐述在J5计算平台上设计高效模型的建议。
注意
下方给出的优化思路,仅做指导建议,所列举案例并不保证对所有场景都适用,请根据实际情况多做尝试。
8.2.2. 通用建议¶
8.2.2.1. 使用BPU算子搭建模型¶
BPU算子本身性能远高于CPU算子,且CPU和BPU之间的异构调度还会引入量化、反量化节点,其计算因为需要遍历数据,所以耗时也与shape大小成正比。
对于模型尾部输出的反量化,和featuremap模型输入的量化节点,我们建议通过 hb_model_modifier 工具手动摘除,
并将相关操作合入前、后处理代码中,从而节省一次数据遍历的冗余耗时。同时在模型后处理中还可考虑先完成筛选过滤的操作,仅对剩下的数据做反量化,还可进一步压缩耗时。
8.2.2.2. 选择BPU高效实现的Backbone¶
在J5计算平台上,BPU针对GroupConv,甚至DepthwiseConv做了针对性的优化,所以我们更推荐采用Depthwise+Pointwise结构的 MobileNetv2、EfficientNet_lite, 以及地平线基于GroupConv手工设计自研的 VarGNet 作为模型的Backbone, 以便获得更高的性能收益(下表提供了典型分类/检测场景模型在J5上的性能指标作为参考)。需要注意的是:
1.地平线的EfficientNet_lite示例模型来源于 EfficientNet-lite Github地址 , 相比于官方原版实现去除了包含sigmoid查表算子的SE结构,Swish激活替换为ReLU。
2.相较于XJ3处理器,Depthwise Conv算子在J5上的加速比有所下降,因此,对于同样的网络结构,将DepthwiseConv替换成Groupconv(保证每个group内channel 8对齐),可获得精度的提高且不损耗性能。 此外,建议尽量避免使用stride>1时的DepthwiseConv,效率较低。
3.GroupConv每个组内C方向8对齐,否则无效的padding会造成算力浪费。
为了加速算法开发速度以及在地平线计算平台上的部署速度,地平线算法工具链提供了丰富的参考算法,目前已提供了数个高效backbone模型源码, 模型场景覆盖雷达点云、视觉BEV、光流估计、车道线检测、3D检测、transformer等。
8.2.2.3. 尽量提高模型的计算/访存比¶
由于J5算力的显著增加,所以要更多地考虑其带宽压力。地平线常用的提高模型计算/访存比的优化思路包括:
使用GroupConv降低模型深层的weight加载 。当模型channel比较小时,我们可以利用普通的稠密卷积(如3x3)去发挥处理器的强大算力。 而随着模型加深,下采样次数变多,channel会急剧变大,此时建议使用GroupConv来缓解带宽压力。
Block间采用更小的featuremap ,这样可以减少DDR与SRAM之间的数据搬运。
避免使用过大的kernel_size 。过大的kernel_size(>9)一方面会增加weight的参数量, 另一方面会使当前计算依赖过多的前层数据,导致数据搬运更加频繁。
Shortcut不宜过长 。过长的shortcut会导致featuremap在SRAM里驻存的时间过长,甚至会导致数据dump到DDR上。
小图多Batch 。J5因为算力较大,所以在大模型(720P及以上)上的性能表现比较好。 对于小模型(分辨率 <= 256),则建议使用batch模式进行推理,从而降低模型weight的加载次数, 更有效地平衡计算/访存比。
8.2.3. 特殊结构优化建议及示例¶
8.2.3.1. 遵循硬件对齐规则¶
J5计算平台运算的时候有最小的对齐单位,若不满足对齐规则,会对Tensor自动进行padding,造成无效的算力浪费。 不同的算子对齐规则有所差异,以下为一些常见计算在J5上的对齐规则:
运算部件 |
对齐 |
备注 |
|---|---|---|
Conv |
2H16W8C/2H32W4C |
具体对齐以–advice编译提示信息为准 (advice参数说明可参考 编译参数组 中的描述。) |
Resize/Warp |
2H32W4C/2H2W64C |
小于等于4C:2H32W4C 大于4C:2H2W64C |
Pooling |
2H16W8C/256C |
Kernel[2,2]/[3,3]:2H16W8C 其他:256C |
Elementwise |
2H16W8C |
—— |
Reduce |
256W/256C |
Reduce on axis W: 256C Reduce on axis C: 256W |
注解
2H16W8C,表示计算的时候H方向对齐到2, W方向对齐到16,C方向对齐到8,即假如原始tensor shape为 (1, 1, 20, 10) (layout: NHWC), 实际运行时的tensor shape将被padding至 (1, 2, 32, 16)。
8.2.3.1.1. 大数放在W维度¶
由上方表格,我们可以发现对于Conv、Elementwise等常见计算,W的对齐要求都高于H和C,因此,在模型设计时我们可以考虑尽量将数据放在W维度上,其次是C,最后才是H。
例如:
原始模型 |
优化方式1 |
优化方式2 |
|
|---|---|---|---|
优化方式 |
—— |
通过插入transpose交换h和w |
直接交换模型输入的h和w |
模型结构 |
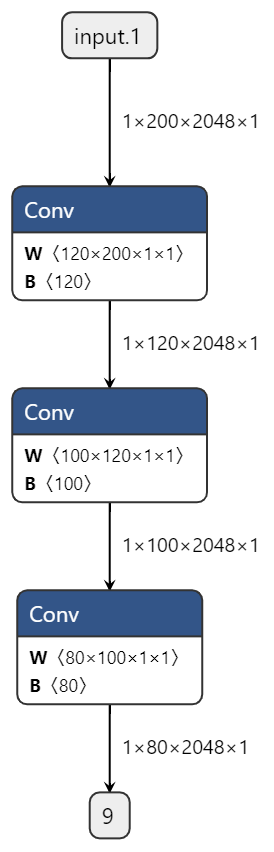
|
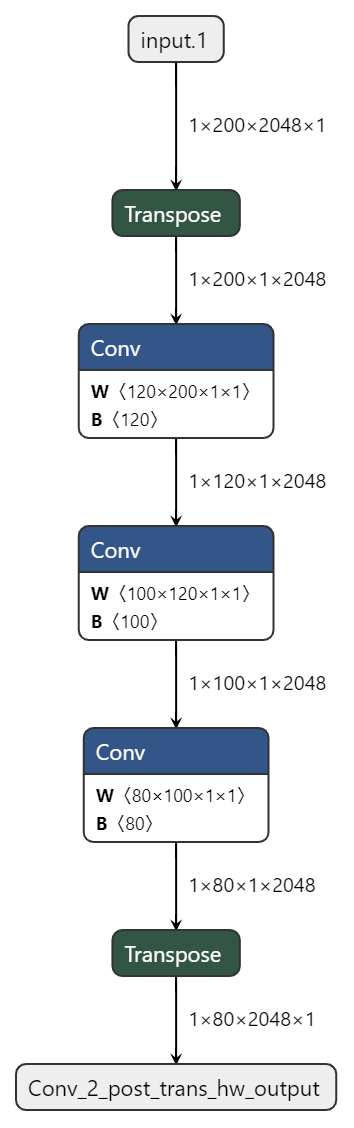
|
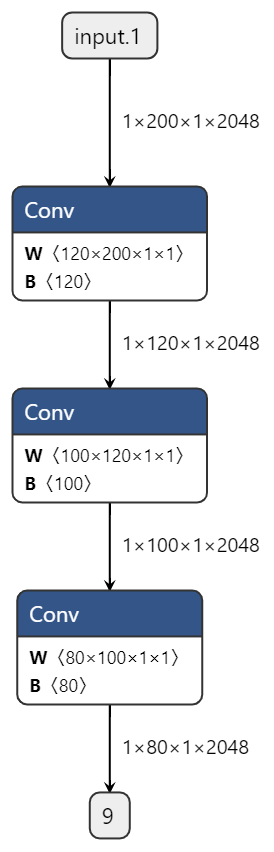
|
预估耗时 |

|
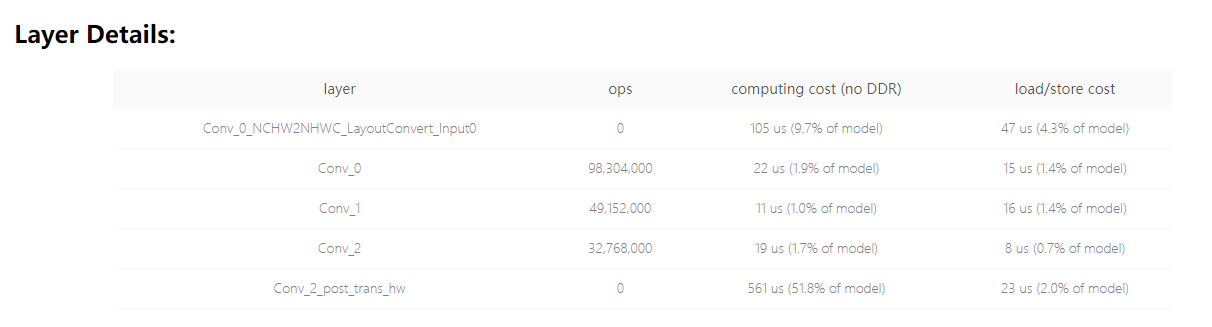
|

|
板端实测单帧延时(ms) |
7.3222 |
2.7619 |
0.5034 |
可见将大数放到w维度之后,对模型性能的增益效果是非常明显的,由于transpose又会引入额外的耗时,因此参考优化方式2直接改写模型输入尺寸会是最高效的做法。
8.2.3.1.2. 减少算子类型的切换¶
由于不同算子的对齐规则是有区别的,因此在算子类型切换的时候除了数据对齐浪费的开销,还会引入数据重排的开销(例如2H16W8C向256C重排)。 因此建议构建模型时尽量避免不同类型算子之间的反复切换。
例如:
原始模型 |
优化方式 |
|
|---|---|---|
优化方式 |
—— |
将reducesum替换为kernel size=1, input channel=C,output channel=1的conv |
模型结构 |
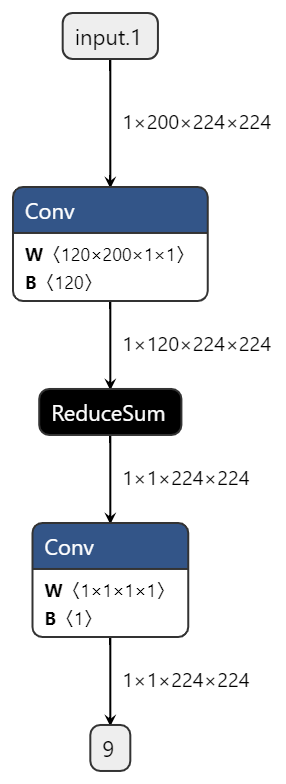
|
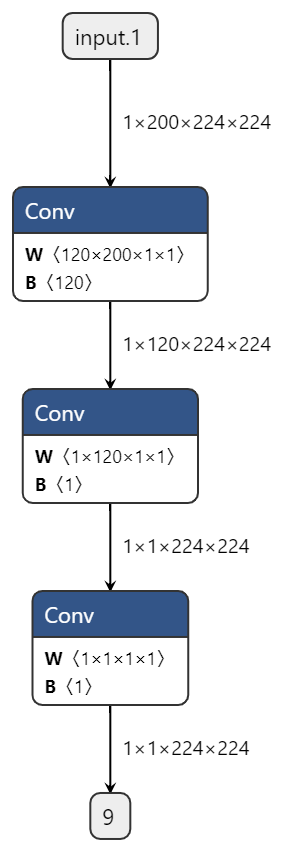
|
预估耗时 |

|

|
板端实测单帧延时(ms) |
1.8065 |
1.7874 |
8.2.3.2. 减少数据transform操作¶
J5 BPU是张量运算处理器,数据排布是多维表示,而Reshape、Transpose的表达语义是基于CPU/GPU的线性排布,因此在BPU上进行数据transform操作是会引入部分耗时的。
8.2.3.2.1. 减少使用reshape、transpose等操作¶
例如:
原始模型 |
优化方式 |
||
|---|---|---|---|
优化方式 |
OE1.1.48版本后对nn.MultiheadAttention有一些优化 |
手写四维self-attention, 并确保feature位于W维度 |
|
模型结构 |
原始模型 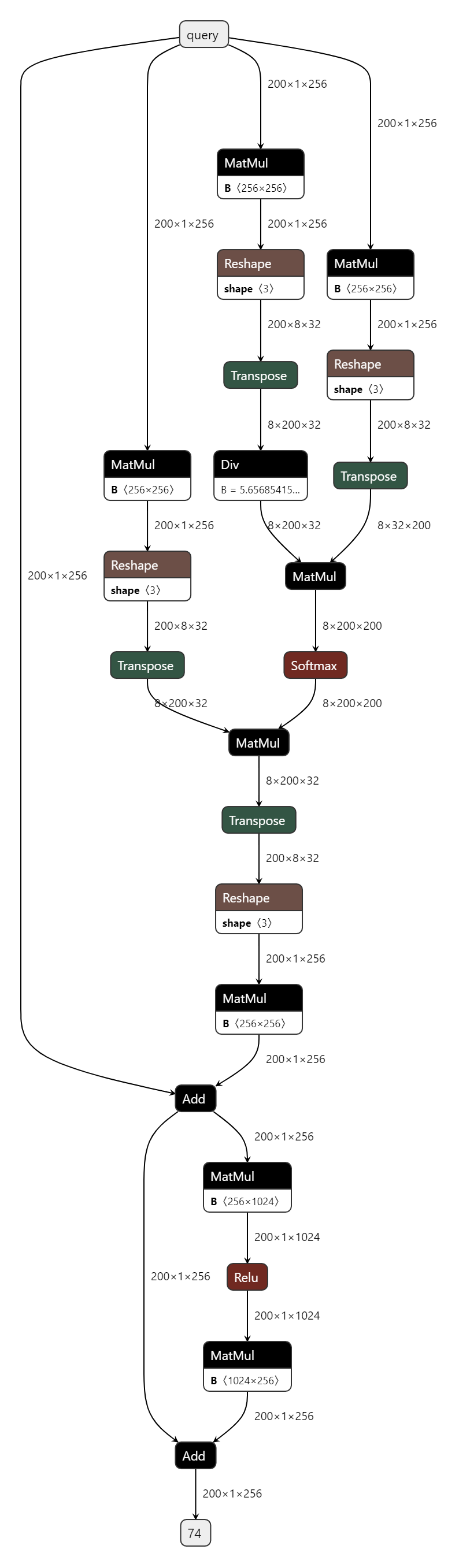
|
optimize模型 
|
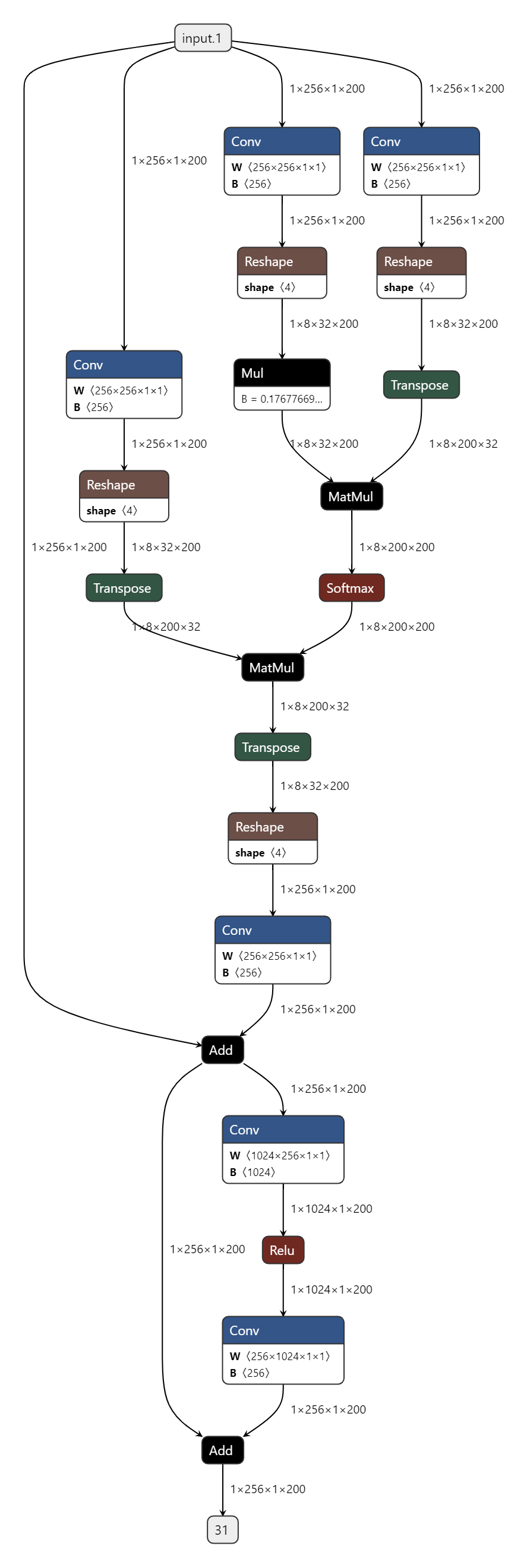
|
预估耗时 |
—— |
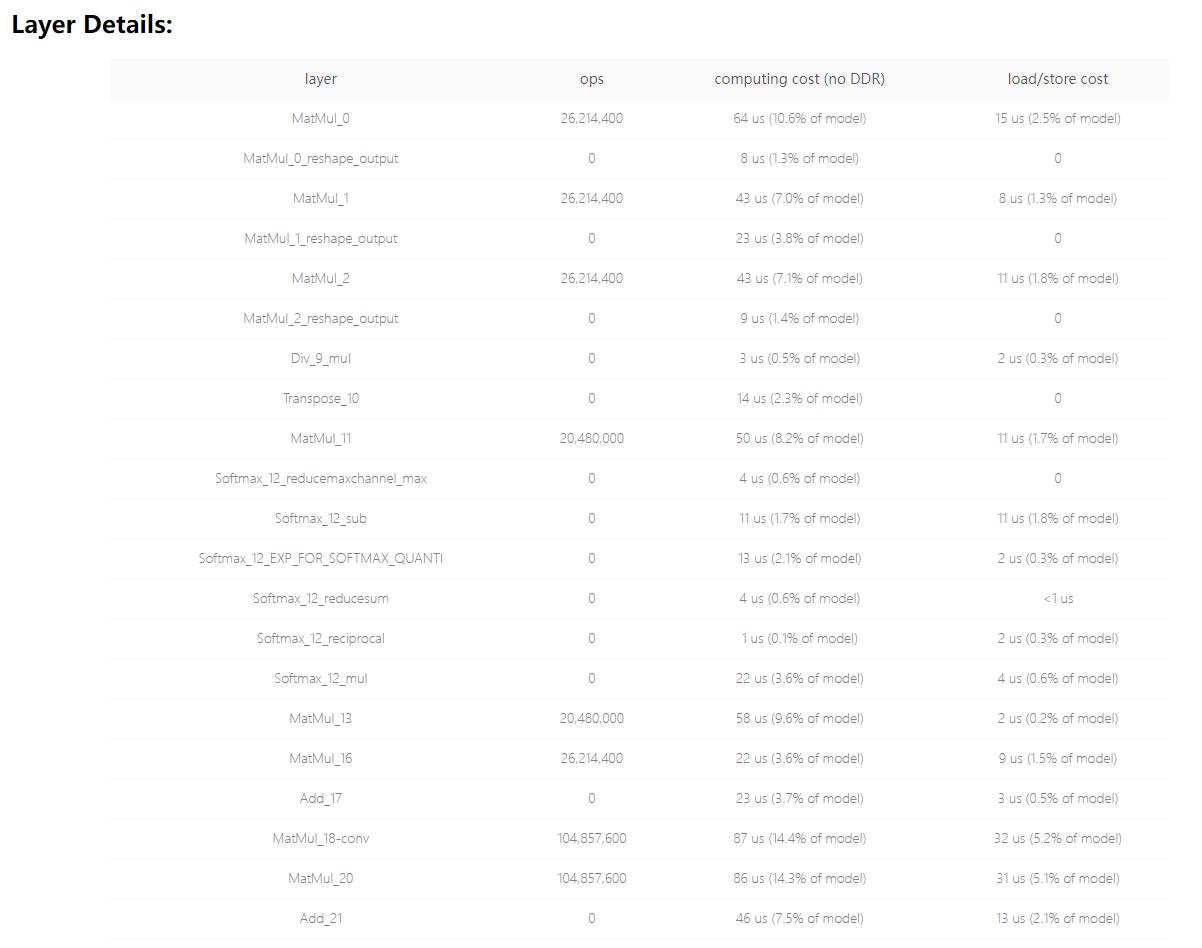
|
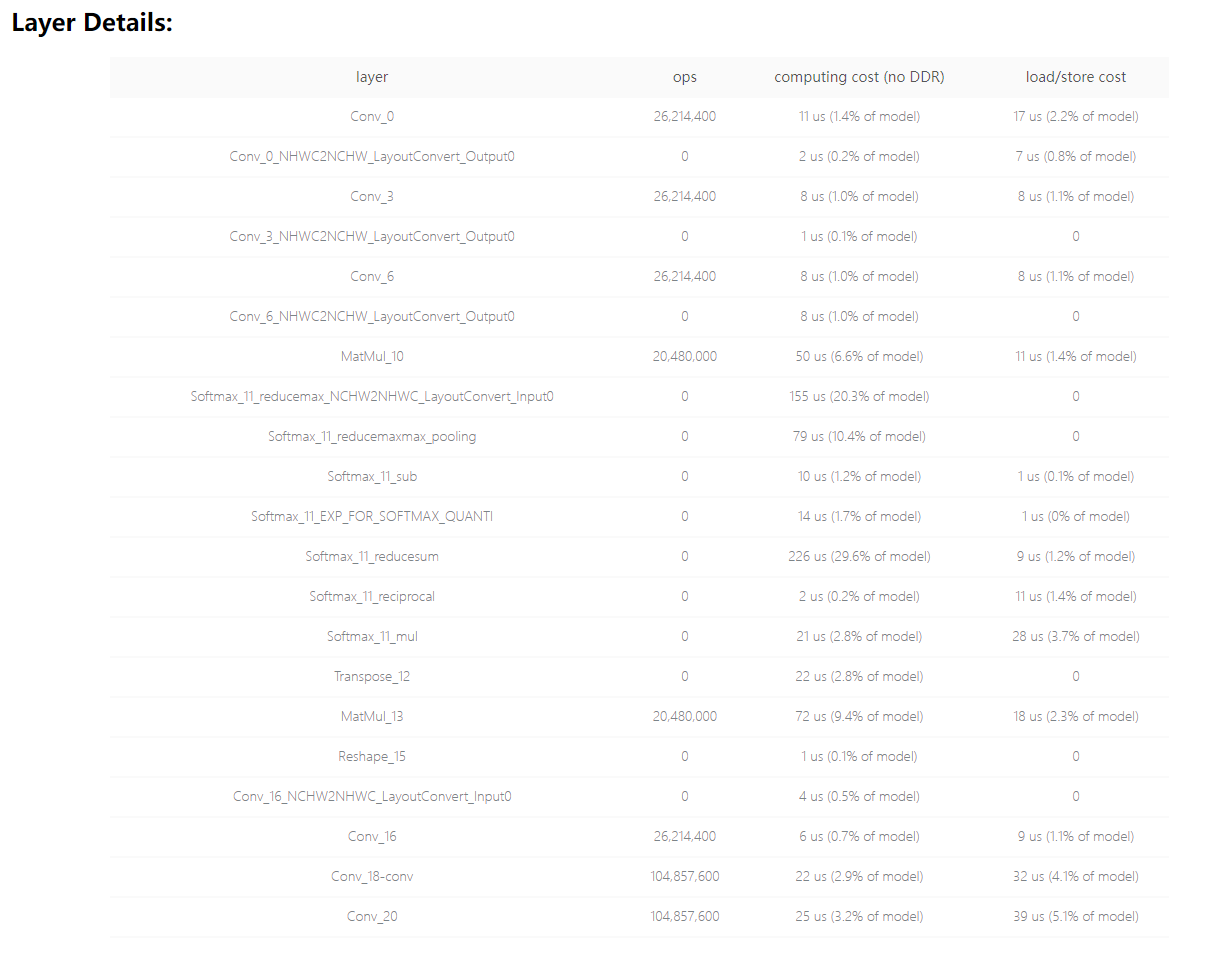
|
板端实测单帧延时(ms) |
—— |
0.8728 |
0.6849 |
地平线转换工具会将matmul、gemm等op等价转换为conv2d计算,或多或少会引入额外的data transform操作以及add无法被吸收等问题, 因此建议设计模型时将nn.Linear、nn.MultiheadAttention等原生非四维的计算重新改写为四维计算,并尽可能用conv2d等价替代一些操作。
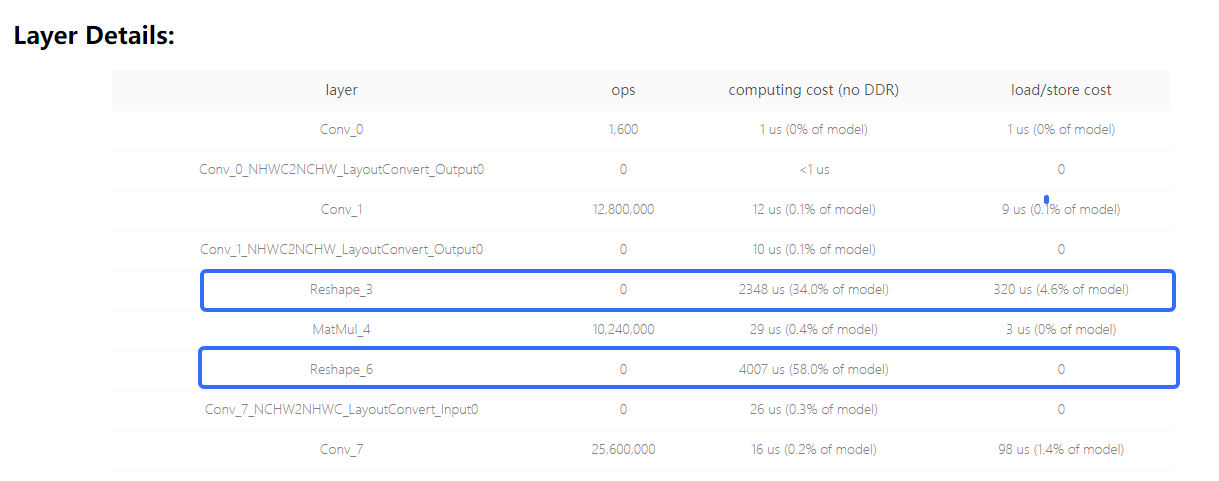
8.2.3.2.2. reshape时减少改动的维度¶
使用reshape操作时,改动的维度越多,计算效率越低。在这个已知特性的前提下,可见下方例子:
原始模型 |
优化方式 |
|
|---|---|---|
优化方式 |
—— |
matmul左右矩阵均支持batch维度的广播, 因此可减少reshape改动维度 |
模型结构 |
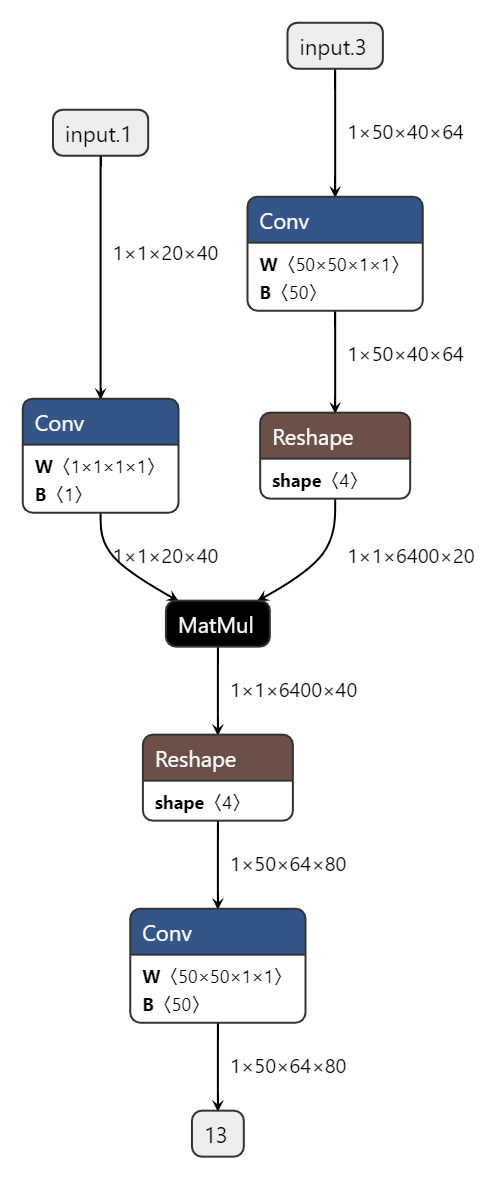
|
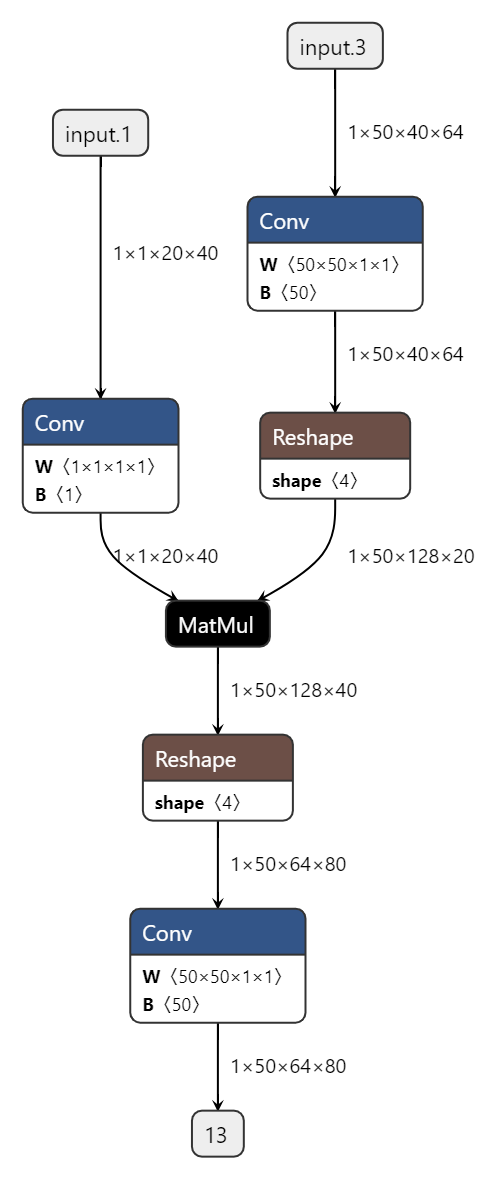
|
预估耗时 |
|

|
板端实测单帧延时(ms) |
6.9992 |
0.5795 |
由于地平线工具链支持matmul两个输入矩阵的batch维度(指除最低两维外的其他维度)广播,因此依据计算逻辑,通过减少reshape改动的维度可明显降低延时。