1. 后量化转换 (PTQ)¶
1.1. 模型准备&算子支持¶
1. 如何准备地平线支持转换的浮点模型?
答:地平线 PTQ 浮点转换工具链支持 Caffe1.0 和 ONNX(opset_version=10/11 且 ir_version≤7)两种模型格式。 ONNX 导出方式参考如下:
训练框架 |
ONNX导出方式 |
|---|---|
Caffe1.0 |
地平线原生支持,无需导出ONNX |
Pytorch |
|
TensorFlow2 |
|
PaddlePaddle |
|
其他框架 |
2. 如何验证原始浮点 ONNX 模型的正确性?
答:工具链在转换模型时,会使用基于公版 ONNXRuntime 封装的接口实现模型的解析和前向,所以我们应该在使用工具链之前先检查原始浮点 ONNX 模型本身的合法性(即是否能够正常推理), 以及从训练框架导出 ONNX 的过程中是否引入了精度偏差。具体测试方式可参考: HB_ONNXRuntime 基础使用 <2.1 原始 ONNX 模型推理> 章节。
3. 如何转换 fp16 的模型?
答:工具链目前不支持 fp16 模型的直接转换,但可参考文章 如何将FP16的ONNX模型转为工具链支持的FP32的ONNX模型 将其先转换成 fp32 模型,再使用地平线工具链进行量化转换。
4. 如何修改 featuremap 模型的输入 layout?
答:通常四维 featuremap 输入模型的输入排布为 NCHW,即 input_train_layout: NCHW,但有时为了适配端侧 runtime 输入数据排布,就希望能修改编译后 bin 模型的输入 layout 为 NHWC。
如果直接配置 input_rt_layout: NHWC,则 bin 模型结构为 Transpose(CPU) + Quantize(CPU) + model(BPU);此时如果还想删除 Quantize 节点合入前处理,则必然需要先删除更前端的 Transpose 节点,这将不符合预期。
- 所以我们需要从模型层面修改,建议使用如下方式实现:
在 DL 框架中增加 transpose,使其输入 layout 为 NHWC,并重新导出 ONNX 模型;
使用 onnx 库直接修改模型,参考如下:
import onnx
onnx_model = onnx.load('./model.onnx')
graph = onnx_model.graph
new_node = onnx.helper.make_node( # 创建Transpose节点
"Transpose",
inputs = ["data"], # 新输入节点名称,自定义
outputs = ["data_oringal"] # 原输入节点名称
perm = [0, 3, 1, 2] # NHWC-->NCHW
)
graph.node.insert(0, new_node) # 将Transpose插入在模型最前端
d = graph.input[0].type.tensor_type.shape.dim # 配置新模型输入,NHWC
d[0].dim_value = 1
d[1].dim_value = 224
d[2].dim_value = 224
d[3].dim_value = 6
onnx_model.graph.input[0].name = f"data" # 配置模型输入名称
onnx.checker.check_model(onnx_model) # 模型检查
onnx.save(onnx_model, "new_model.onnx") # 保存新模型
模型成功修改后,即可配置 input_rt_layout: NHWC、input_train_layout: NHWC,这样编译出的模型将自动消除前端的 transpose,直接以 NHWC 排布输入,模型前端只保留一个 CPU 运行的 Quantize 节点,可使用 hb_model_modifier 工具进一步删除。
1.2. 模型转换¶
1. 如何理解 shape_inference_fail.onnx?
答:该模型只会在 PTQ 模型转换失败时产出,对用户无特殊意义,可向地平线提供该模型和模型转换时的 log 文件进行 debug 分析。
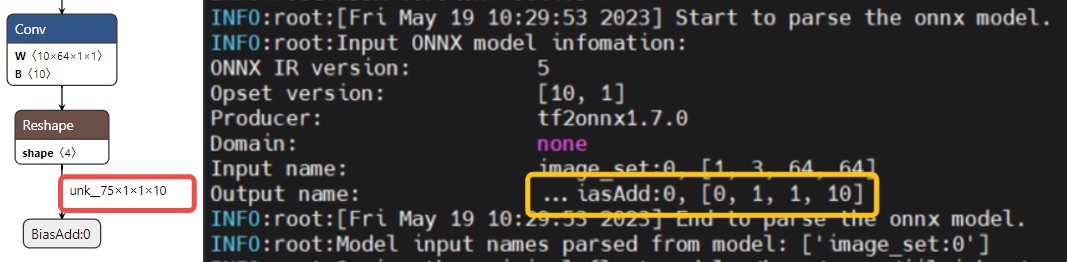
2. 如何理解 log 中模型输入输出 shape 为 0?
答:模型转换日志会打印模型的输入输出节点的 name 及 shape,但有时也会出现 shape 为 0 的情况,如下图所示。 其主要发生在 batch 维度,因为某些模型的输出 shape 是动态的(使用 dim_param 来存储),转换工具前向推理模型(shape_inference)后就会使用?来占位,此时日志打印就会显示为 0。 这种情况是符合预期的,不会影响模型转换,用户无需过分关注。
3. 如何理解某些算子符合约束,却运行在 CPU 上?
答:XJ3 平台因为没有专门的查表硬件,所以当查表算子(通常为非线性的激活函数)运行时的硬件对齐尺寸超出 8192 时就会被自动回退至 CPU 运行,此时模型转换的日志中也会有相关 warning 打印。
除此之外,XJ3 和 J5 平台的某些算子还会因为被动量化的原因运行在 CPU 上,其原理说明可参考文章: 模型转换工具链中的主动量化和被动量化逻辑 。
1.3. 模型性能¶
1. 是否有硬件支持模型输入颜色空间转换?
答:BPU 支持常见模型输入格式间的转换(例如 nv12 -> rgb/bgr)和数据归一化,可以通过 yaml 文件进行配置。
具体请见 input_type_train、input_type_rt、norm_type 等参数的说明。
配置后工具链将以 BPU 算子的形式将其集成在模型中,此时请勿在前处理中重复操作。
2. 如何理解编译器优化等级?
答:yaml 文件 optimize_level 参数可配置 O0~O3 的编译器优化等级,优化等级越高则搜索空间越大。
另外也有一些比较耗时的优化策略是在 O2 或 O3 阶段才会启用。
优化等级并不会针对算子粒度层面进行一些确定的优化策略,大部分算子的优化与优化等级没关系(这些优化不耗时)。
优化等级主要是对全局优化起作用,是结合整个模型进行的分析和优化。
3. 如何处理模型首尾部的量化/反量化算子?
- 答:PTQ 工具链默认会在 featuremap 输入模型的首部插入量化算子来实现输入数据从 float32 到 int8 类型的映射,并在所有模型的尾部插入反量化算子来实现输出数据从 int8(若 BPU 以 conv 结尾则默认为 int32 输出) 到 float32 的映射。而量化/反量化算子在 CPU 上的执行效率并不高,特别是在数据 shape 比较大的时候。所以我们更建议通过以下两种路径来解决:
将量化/反量化操作融合进前后处理,此种方式最为高效,具体说明请见:反量化节点的融合实现;
J5 工具链自 OE-v1.1.37 版本起也提供了对应的 DSP 接口,具体说明请见:工具链用户手册 10.3.1.6.2 节。
4. 如何使用 unitconv 算子优化模型性能?
答:模型中的一个算子能运行在 BPU 上,除了其本身应满足 BPU 支持条件外,还需要能在校准时找到它的量化阈值。 而部分非计算密集型算子(如 concat,reshape 等)的量化阈值会依赖于上下游算子的 featuremap Tensor。 因此,若这些算子在模型首尾处就会默认跑在 CPU 上。 此时若想追求更高效的性能,可以在该算子前/后插入 unitconv 来引入新的量化阈值统计,进而将其量化在 BPU 上。 具体说明可见:unit_conv使用说明(用于优化模型性能)。
但需要注意的是,这种方法有可能会引入一定的量化损失。
以 conv+reshape+concat 结构输出的模型为例,
工具链默认 conv 会以 int32 高精度输出,反量化至 float32 后再送给 CPU 上的 reshape 和 concat。
若在 concat 之后插入 unitconv,则整个结构都将以 int8 低精度运行在 BPU 上,
此时虽然最后的 unitconv 还能以 int32 高精度输出,但前面 conv 输出的精度压缩已经引入了一定的量化损失。
所以,是否插入 unitconv 来优化性能还请综合考虑。
1.4. 模型精度¶
1. J5 芯片是否支持 int16/int32 计算?
- 答:J5 芯片在陆续开放部分算子 BPU int16 的支持能力,具体可见 算子支持列表,另外:
若模型中的 BPU 部分以 Conv 结尾,则该算子默认为 int32 高精度输出;
J5 芯片上的 DSP 硬件也具备 int8/int16/float32 的计算能力。
2. 如何正确处理模型的校准数据?
- 答:PTQ 模型校准数据的准备请参考 工具链用户手册 6.3.3 节,另外:
对于图片输入的模型,还可以参考文章: 图片校准数据准备问题介绍与处理;
对于 featuremap 输入的模型,请自行完成数据的预处理,并通过 numpy.tofile 接口保存为 float32 类型的文件。
3. 如何 dump 模型中间层输出?
答:在模型转换阶段,yaml 文件中的 layer_out_dump 参数如果配置为 True,则会为每个卷积算子增加一个反量化输出节点,它会显著的降低模型上板后的性能,一般用于配合 vec_diff 向量比较工具使用,但该工具已基本弃用,所以并不推荐。
相比之下,output_nodes 参数可以指定模型中的任意节点为输出节点,更利于我们调试调优。 此外,还可以使用 hb_verify 工具对比模型在开发机 Python 端和开发版 C++ 端的输出一致性。
在板端部署阶段,hrt_model_exec 工具也支持以 bin 或 txt 的格式保存节点输出(包括用 output_nodes 参数指定的节点),具体使用方式可参考: hrt_model_exec新增参数说明。
1.5. 常见故障¶
1. assert len(attribute.ints) == 4
File "/usr/local/lib/python3.6/site-packages/horizon_tc_ui/hbdtort/onnx2horizonrt.py", line 403, in convert_conv
assert len(attribute.ints) == 4
AssertionError
答:该报错主要发生在模型检查阶段,是模型中存在暂不支持的三维算子 Conv1d 导致,建议更换成 Conv2d。
2. Segmentation fault:core dumped
- 答:该报错可能是物理机内存不足,工具版本老旧,模型非法,或工具 bug 导致。请通过以下方式进行排查:
确认当前物理机是否存在其他任务正在占用内存(或更换至更大内存的开发机);
升级工具链版本至最新,重新转换模型;
确认原始模型本身是否合法,如 onnx 模型是否能在 onnxruntime 中正确运行;
若以上检查后仍无法解决,请联系地平线团队。
3. ERROR cannot reshape array of size xxx into shape (x, xxx, xxx)
- 答:该报错主要发生在模型校准阶段,是校准数据的类型或尺寸与模型不匹配导致。可以进行如下检查:
校准数据 shape 与模型输入 shape 是否正确匹配;
图片数据预处理时的读取方式是否正确,例如 opencv 读取为 0~255 的 u8 数据,颜色通道为 BGR;skimage 读取为 0~1 的 fp32 数据,颜色通道为 RGB;
非图片数据是否以正确的类型存储,目前工具链只支持 fp32 类型的数据;
yaml 文件中的
cal_data_type参数是否与保存的校准数据类型正确匹配。
4. ERROR Wrong mean_value num received
ERROR yaml file parse failed. Please double check your config file inputs
ERROR Wrong mean_value num received. input mean_value num n is not equal to input num m
答:该报错是 yaml 文件中的 mean_value 参数数量与模型输入节点数量不一致导致,请对应检查。
不同输入节点的 mean_value 需要用 “;” 号隔开;
若模型为混合多输入模型(即同时包含图像和 featuremap 输入节点),
则需要与 input_name 对应,用 “NA” 给 featuremap 节点的 mean_value 参数占位。
5. ERROR The input model is invalid
答:该报错是模型本身非法导致,即不满足公版 onnxruntime 的检查逻辑,请自行检查模型,地平线暂不提供此类问题的支持。
6. ERROR [ONNXRuntimeError]: This is an invalid model
答:该报错主要发生在模型解析阶段,请使用公版 ONNXRuntime 或地平线 HB_ONNXRuntime 检查原始模型的合法性。 可参考文章 模型精度验证及调优建议 <1.1 验证原始浮点onnx模型的正确性> 章节内容。 若模型无法推理,请自查模型;若模型能正常推理,请联系地平线进行问题分析。
7. CRITICAL can not establish ssh connection to bpu board. authentication failed!
答:旧版 hb_verifier 工具链接有密码的开发板时就会触发如下报错:
File "/usr/local/lib/python3.8/dist-packages/paramiko/auth_handler.py", line 259, in wait_for_response
raise eparamiko.ssh_exception.BadAuthenticationType: Bad authentication type; allowed types: ['publickey', 'password']
2023-07-20 11:22:18,789 CRITICAL can not establish ssh connection to bpu board. authentication failed!
- 此时建议:
更新版本至 J5-v1.1.63 或 X3-v2.7.2 版本;
或在当前环境中,使用 ssh-keygen 生成 ssh-key,再使用
ssh-copy-id {username}@{board_ip}配置公钥至开发板,即可正常使用。