4. 参考算法 (J5)¶
4.1. 通用问题¶
1. 如何找到 config 文件中模块的具体实现?
答:模块对应的实现为 type 对应的 value,可将 type 值理解为 class,在 build model 时会实例化该类, 类的路径可通过以下两种方式获取:
(1)各模块的具体实现存放在 hat/models/模块名/,也可以在 __init__.py 中查看该路径下是否包含该 class,
例如在 bev_mt_ipm 模型的配置文件中,neck 的 dict["type"] 为 "FastSCNNNeck",
则 FastSCNNNeck 的实现在 hat/models/necks/fast_scnn.py;
另外,特定 task 的模块定义会在 task_modules 下(head,后处理,decoder),
例如检测分支的 head 配置项为 "CenterPoint3dHead",是 task_modules 包含部分,
则其实现在 hat/models/task_modules/centerpoint3d/head.py;
(2)使用 grep 命令查找,例如:
grep -rn "class $type_value$" $HAT_PATH$
2. config 正常打印,但 launch trainer 失败
答:例如以下报错需要修改 config 中的 device_ids 为当前可使用的 GPU 资源;
若报错包含 “CUDA out of memory”,则需修改 batch_size_per_gpu 为当前资源能支持的 batch size。
Traceback (most recent call last):
File "/root/.local/lib/python3.6/site-packages/torch/multiprocessing/spawn.py", line 59, in _wrap
fn(i, *args)
File "/usr/local/lib/python3.6/site-packages/hat/engine/ddp_trainer.py", line 394, in _main_func
torch.cuda.set_device(local_rank % num_devices)
File "/root/.local/lib/python3.6/site-packages/torch/cuda/__init__.py", line 311, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
3. 为什么配置 data 运行的 device 不生效?
答:请在 hat/engine/processors/processor.py 中检查 to_cuda 是否成功,
不成功可能是因为 data 不是 tensor 类型导致未调用起 device。
4. 为什么配置 trainer 的运行 device 不生效?
答:device 和 device_id 配置有优先级:如果使用默认的 train.py 的 launch 来调用的 trainer, 那么只有 device-ids 是起作用的,device 配置不会起作用。 如果是直接调用的 trainer(predictor,loop base等),device 可以直接起作用。
5. 如何设置验证/打印频率?
答:在 config 文件中有关于 callback 频率的参数,验证频率可以通过以下方式修改,其他 callback 相关频率都以 “xxx_frep” 形式设置:
val_metric_updater = dict(
type="MetricUpdater",
metrics=[val_nuscenes_metric, val_miou_metric],
metric_update_func=update_val_metric,
step_log_freq=10000,
epoch_log_freq=1, # 此处配置
log_prefix="Validation " + task_name,
)
6. 为什么 plt.show 图像不显示?
答:可能是由于当前 Linux 系统无图形界面导致,可以在 hat/visualize 路径下各数据集对应代码中添加
plt.savefig('./test.png',dpi=300),保存在本地后再查看。
7. 如何 new dataset?
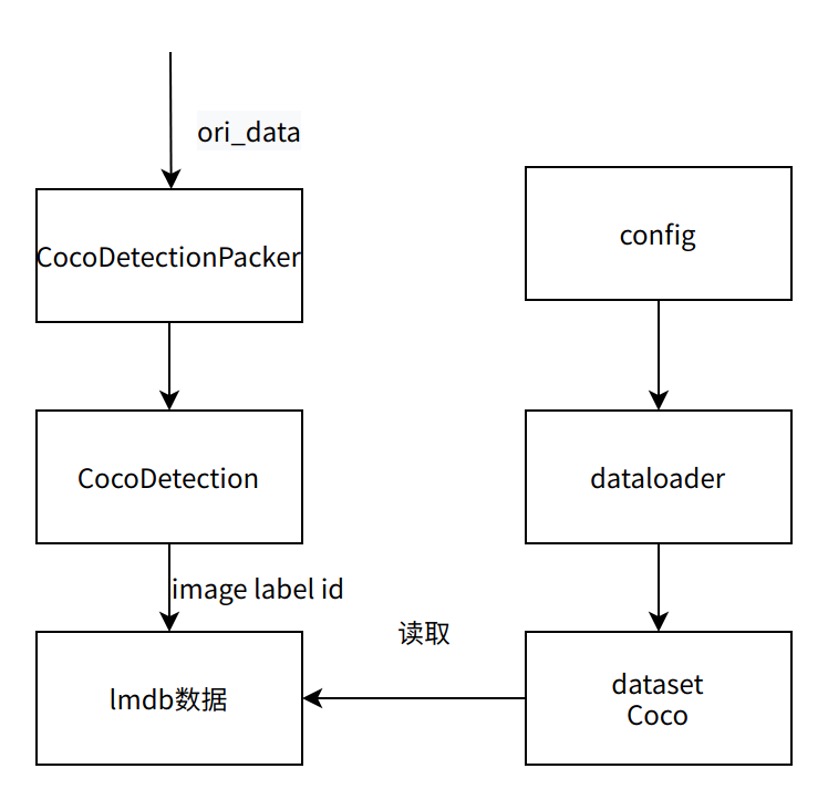
答:dataloader 内部类调用流程图如下所示(以 Coco 数据集为例),其中所有类和接口都在config中调用,
数据加载通过调用 dataloader 实现,dataloader 加载的数据集 dataset 由 Coco 类返回,
Coco 类读取的是lmdb 格式的打包数据,该数据通过调用 packer 接口实现,
实现流程: packer 调用 CocoDetectionPacker 类将 CocoDetection 返回的数据(image,label…)打包成设置的格式(lmdb,mxrecord)。
实现一个 dataset 需要对以上涉及的类重写,
根据数据集的 format(也可将数据集的 format 调整为原 dataset 的格式)重写 __getitem__()。
8. 如何恢复意外中断的训练?
答:可以通过在 config 的 {stage}_trainer 中配置 resume_optimizer 和
resume_epoch_or_step 字段来恢复意外中断的训练,或仅恢复 optimizer 来进行 fine-tune,
例如在 config 文件的 trainer 中增加以下字段:
# 恢复optimizer和LR的状态
resume_optimizer=True,
# 恢复epoch和step
resume_epoch_or_step=True,
model_convert_pipeline=dict(
type="ModelConvertPipeline",
converters=[
dict(
type="LoadCheckpoint",
checkpoint_path=os.path.join(
# 加载模型参数
ckpt_dir, "float-checkpoint-best.pth.tar"
),
),
],
)
9. 如何可视化模型结构?
答:可参考: 如何可视化地平线的参考算法模型结构。
10. 如何修改 calibration 的方法?
答:可以修改 config 中的 calibration_trainer 字段,新增 qconfig_params 字典,参考如下:
calibration_trainer = dict(
type="Calibrator",
model=model ,
model_convert_pipeline=dict(
type="ModelConvertPipeline",
qat_mode="fuse_bn",
qconfig_params=dict(
activation_calibration_observer="percentile",
activation_calibration_qkwargs=dict(
percentile=99.975,
),
),
converters=[
dict(
type="Loadcheckpoint",
checkpoint_path=os.path.join(
ckpt_dir, "float-checkpoint-best.pth.tar'
),
),
dict(type="Float2Calibration", convert_mode=convert_mode),
],
),
......
4.2. DETR模型¶
1. 是否支持 deformable conv?
答:该算子主要在 deformable-DETR 中的 deformable attention 结构中使用,地平线还暂不支持, 但可以使用已经支持的 gridsample 算子进行替代。
4.3. BEV模型¶
1. 为什么 Lss 的精度低于 IPM?
答:Lss 的输入分辨率是 256x704, 低于 IPM 的 512x960,所以精度更低。
2. Lss 输入的约束条件是什么?
答:Lss 在 grid_sample 前会做维度折叠,所以对 input_feature 的 h、w 有算子编译的约束条件,
目前为:H,W ∈ [1, 1024] 且 H*W ≤ 720*1024。
3. Lss 的 mul(depth,feature) 耗时大如何解决?
答:可以先通过 grid_sample 算子将 featuremap 的 H、W 转换为 [128,128] 后再做 mul 计算。
4. Lss 的 voxelpooling 如何实现?选取多少个点?
答:为了不遗失坐落在相同 voxel 中的点云特征,我们会对每个 voxel 采样 10 次, 并将每个点云特征相加得到 128x128x64 的 BEV 特征图,对应代码如下:
num_points=10
for i in range(self.num_points): # 每个voxel采样10次
homo_feat = self.grid_sample(
feat,
self.quant_stub(points[i]),
)
homo_dfeat = self.dgrid_sample(
dfeat,
self.dquant_stub(points[i + self.num_points]),
)
homo_feat = self.floatFs.mul(homo_feat, homo_dfeat)
trans_feat = homo_feats[0]
for f in homo_feats[1:]:
trans_feat = self.floatFs.add(trans_feat, f) # 点云特征相加
5. Lss 如何选择参考点?
答:point 的生成在 _gen_reference_point,会将 feature 范围外的无效点置为较大的值。
为了不取到无效点,会使用 topk(k=10,训练速度较快)将取值较小的前 10 个点进行集合。
6. Lss 如何处理 gridsample 输入较大的情况?
答:Lss 模型因为会在 gridsample 算子前将 3 个维度折叠为 1 个维度,因此其 H*W 容易超出 720*1024 的 BPU 算子约束限制。
此时建议在维度折叠(即 dfeat = dfeat.view(B, 1, -1, H * W))前,先对可能超限的维度进行拆分,分别计算 gridsample,最后再将结果叠加。
7. 为什么 gkt 的精度指标较低?有什么优势?
答:基于 Transformer 的 gkt 精度低于 IPM 的主要原因是开源数据集的数据量不够, 我们尝试加入一些业务数据后可以高于 IPM 的精度。而且 gkt 模型的鲁棒性更好,能够解决相机偏移导致的精度影响。
8. gkt 的 transfomer 是否是 global 的?
答:不是 global 的,选取的是 kernel(3x3) 的 feature 做注意力,因此是 kernel-transformer。
9. 是否支持公版 bevformer?
答:需要做改动,且性能相对较差,如果想要使用基于 transformer 的方案建议参考 gkt 模型。
10. 检测和分割任务之间是否会制约精度?
答:会有影响,多任务中的检测任务精度会有所下降,需要通过训练策略做平衡。
11. 何获取相机内外参和 homography 矩阵?
答:可参考: 地平线bev参考算法板端输入数据准备教程。
4.4. PointPillars模型¶
1. 模型的 latency 包括哪几部分?
答:Pointpillars 目前的 latency 为:25.8ms+ 2.6ms, 前者包括前处理(voxel化),即点云输入后到 head 的时间;后者则为后处理时间。
2. 点云量对模型性能影响如何?
答:有效点云数越多则前处理耗时越长,具体到配置项为 Voxelization cfg 参数组:
# Voxelization cfg
pc_range = [0, -39.68, -3, 69.12, 39.68, 1] # 有效点云范围
voxel_size = [0.16, 0.16, 4.0] # voxel大小
max_points_in_voxel = 100 # voxel中最大点数
max_voxels_num = 12000 # voxel 个数
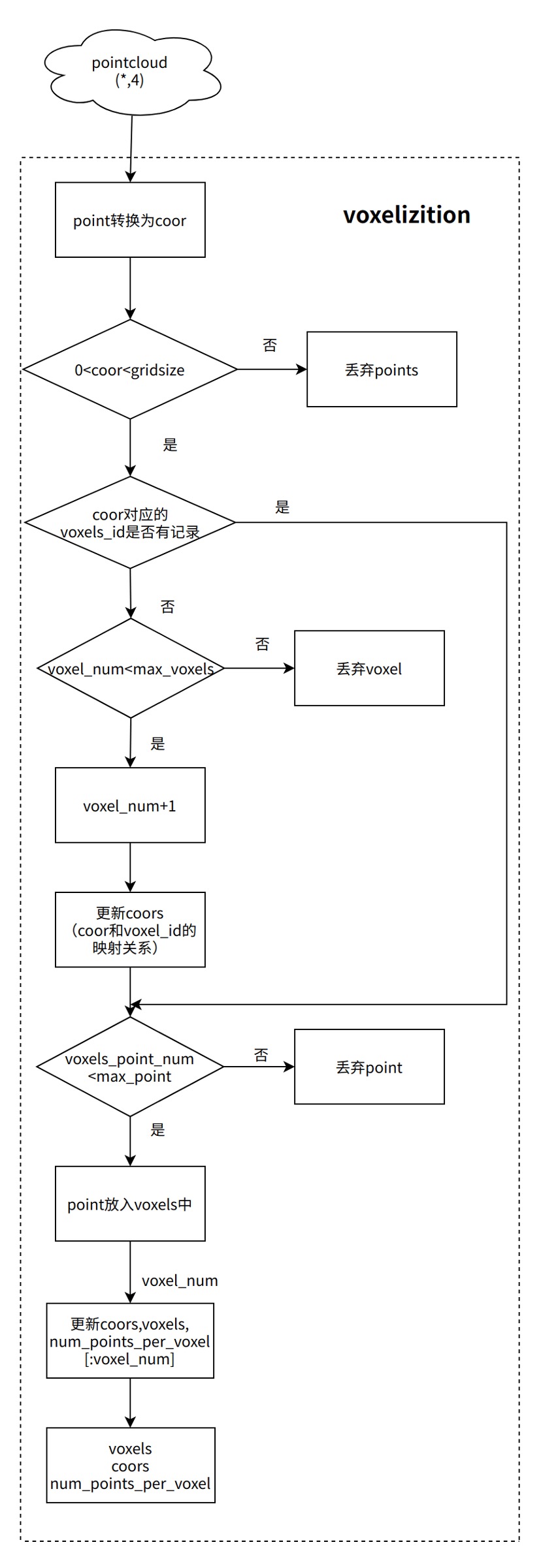
3. 前处理包含哪些操作?
答:前处理为 pillar(voxel)化,对应阶段为 voxeliza tation,流程示意图如下所示:
4. 支持几类任务检测?如何扩展?
答:目前的参考模型仅支持 car 一类检测,多类需要其 NMS 方案(可参考 hat/models/utils.py 中的 multi_class_nms 实现)和对应的 config 配置。
另外,地平线也正在开发多类别检测示例,会在后续与大家见面。
5. 板端 hbm 模型的输入数据如何生成?如何预处理?
答:数据预处理包括 reshape 和 padding(padding 至(1,1,150000,4),其中 150000 为 bin 文件中的最大点云量), 参考代码如下所示:
#padding bin
padding_np=(np.ones(150000*4)*-100).astype(np.float32).reshape(1,1,-1,4)
for f in os.listdir(list_dir):
ori_bin=np.fromfile(os.path.join(list_dir,f), dtype=np.float32).reshape(1,1,-1,4)
con_bin=np.concatenate((ori_bin,padding_np),axis=2)
pad_bin=con_bin[:,:,:150000,:]
if not os.path.exists(save_path):
os.mkdir(save_path)
with open(os.path.join(save_path,f),"w") as sf:
print("the pad file is saved in:",os.path.join(save_path,f))
pad_bin.tofile(sf)
6. 为什么板端 perf 数据与官方指标不一致?
答:在板端使用 hrt_model_exec perf 工具评估性能时请指定真实的 input_file,否则工具会采用随机生成的点云数据,
可能导致 perf 指标不准确。
7. PTQ 方案是否支持 Lidar 模型转换?
答:功能链路上是支持的,可以从训练框架中导出 ONNX 模型进行 PTQ 转换检查。 但是从既有经验看,Lidar 点云模型走 PTQ 方案量化的精度风险较大,主要原因包括:点云比较稀疏,数据分布情况对量化不友好等。
8. centerpoint 和 pointpillars 能否互用?
答:两个模型可以互用,只需要对应修改数据集所涉及的相关配置,例如:点云范围、预测类别,以及后处理的 anchor、target 等, 详情说明可见该技术贴 centerpoint使用kitti数据集过滤后数据集没了 的评论区。
4.5. Swin-T模型¶
1. ONNX 模型导出报错

答:该报错是 torch 社区 1.13 版本 torch.meshgrid 接口引入的 bug,老版本下仍支持导出,如需 Swin-T 参考算法的 ONNX 模型,可在社区发帖咨询。
4.6. DeepLabv3+模型¶
1. 如何实现 Resize 和 Argmax 算子的 BPU 加速?
答:可参考该技术贴 地平线deeplabv3+参考算法如何实现resize和argmax算子的BPU加速? 。