7.3. 快速入门¶
7.3.1. 基本流程¶
量化感知训练工具的基本使用流程如下:

下面以 torchvision 中的 MobileNetV2 模型为例,介绍流程中每个阶段的具体操作。
出于流程展示的执行速度考虑,我们使用了 cifar-10 数据集,而不是 ImageNet-1K 数据集。另外,为了快速展示整体方法和流程,本教程未进行精细地调参提高模型精度,用户实际使用过程中可以根据需求进行调参。
[1]:
import os
import copy
import numpy as np
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torch import Tensor
from torch.quantization import DeQuantStub
from torchvision.datasets import CIFAR10
from torchvision.models.mobilenetv2 import MobileNetV2
from torch.utils import data
from typing import Optional, Callable, List, Tuple
from horizon_plugin_pytorch.functional import rgb2centered_yuv
import torch.quantization
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.quantization import (
QuantStub,
convert_fx,
prepare_qat_fx,
set_fake_quantize,
FakeQuantState,
check_model,
compile_model,
perf_model,
visualize_model,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_calib_8bit_fake_quant_qconfig,
default_qat_8bit_fake_quant_qconfig,
default_qat_8bit_weight_32bit_out_fake_quant_qconfig,
default_calib_8bit_weight_32bit_out_fake_quant_qconfig,
)
import logging
logging.basicConfig(level=logging.INFO, format="%(levelname)s: %(message)s")
[2]:
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name: str, fmt=":f"):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = "{name} {val" + self.fmt + "} ({avg" + self.fmt + "})"
return fmtstr.format(**self.__dict__)
def accuracy(output: Tensor, target: Tensor, topk=(1,)) -> List[Tensor]:
"""Computes the accuracy over the k top predictions for the specified
values of k
"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].float().sum()
res.append(correct_k.mul_(100.0 / batch_size))
return res
def evaluate(
model: nn.Module, data_loader: data.DataLoader, device: torch.device
) -> Tuple[AverageMeter, AverageMeter]:
top1 = AverageMeter("Acc@1", ":6.2f")
top5 = AverageMeter("Acc@5", ":6.2f")
with torch.no_grad():
for image, target in data_loader:
image, target = image.to(device), target.to(device)
output = model(image)
output = output.view(-1, 10)
acc1, acc5 = accuracy(output, target, topk=(1, 5))
top1.update(acc1, image.size(0))
top5.update(acc5, image.size(0))
print(".", end="", flush=True)
print()
return top1, top5
def train_one_epoch(
model: nn.Module,
criterion: Callable,
optimizer: torch.optim.Optimizer,
scheduler: Optional[torch.optim.lr_scheduler._LRScheduler],
data_loader: data.DataLoader,
device: torch.device,
) -> None:
top1 = AverageMeter("Acc@1", ":6.3f")
top5 = AverageMeter("Acc@5", ":6.3f")
avgloss = AverageMeter("Loss", ":1.5f")
model.to(device)
for image, target in data_loader:
image, target = image.to(device), target.to(device)
output = model(image)
output = output.view(-1, 10)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if scheduler is not None:
scheduler.step()
acc1, acc5 = accuracy(output, target, topk=(1, 5))
top1.update(acc1, image.size(0))
top5.update(acc5, image.size(0))
avgloss.update(loss, image.size(0))
print(".", end="", flush=True)
print()
print(
"Full cifar-10 train set: Loss {:.3f} Acc@1"
" {:.3f} Acc@5 {:.3f}".format(avgloss.avg, top1.avg, top5.avg)
)
7.3.2. 获取浮点模型¶
首先,对浮点模型做必要的改造,以支持量化相关操作。模型改造必要的操作有:
在模型输入前插入
QuantStub在模型输出后插入
DequantStub
改造模型时需要注意:
插入的
QuantStub和DequantStub必须注册为模型的子模块,否则将无法正确处理它们的量化状态多个输入仅在 scale 相同时可以共享
QuantStub,否则请为每个输入定义单独的QuantStub若需要将上板时输入的数据来源指定为
"pyramid",请手动设置对应QuantStub的scale参数为1/128也可以使用
torch.quantization.QuantStub,但是仅有horizon_plugin_pytorch.quantization.QuantStub支持通过参数手动固定 scale
改造后的模型可以无缝加载改造前模型的参数,因此若已有训练好的浮点模型,直接加载即可,否则需要正常进行浮点训练。
注意
模型上板时的输入图像数据一般为 centered_yuv444 格式,因此模型训练时需要把图像转换成 centered_yuv444 格式(注意下面代码中对 rgb2centered_yuv 的使用)。
如果无法转换成 centered_yuv444 格式进行模型训练,请参考RGB888 数据部署章节中的介绍,对模型做相应的改造。(注意,该方法可能导致模型精度降低)
本示例中浮点和 QAT 训练的 epoch 较少,仅为说明训练工具使用流程,精度不代表模型最好水平。
[3]:
######################################################################
# 用户可根据需要修改以下参数
# 1. 模型 ckpt 和编译产出物的保存路径
model_path = "model/mobilenetv2"
# 2. 数据集下载和保存的路径
data_path = "data"
# 3. 训练时使用的 batch_size
train_batch_size = 256
# 4. 预测时使用的 batch_size
eval_batch_size = 256
# 5. 训练的 epoch 数
epoch_num = 30
# 6. 模型保存和执行计算使用的 device
device = (
torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
)
######################################################################
# 准备数据集,请注意 collate_fn 中对 rgb2centered_yuv 的使用
def prepare_data_loaders(
data_path: str, train_batch_size: int, eval_batch_size: int
) -> Tuple[data.DataLoader, data.DataLoader]:
normalize = transforms.Normalize(mean=0.0, std=128.0)
def collate_fn(batch):
batched_img = torch.stack(
[
torch.from_numpy(np.array(example[0], np.uint8, copy=True))
for example in batch
]
).permute(0, 3, 1, 2)
batched_target = torch.tensor([example[1] for example in batch])
batched_img = rgb2centered_yuv(batched_img)
batched_img = normalize(batched_img.float())
return batched_img, batched_target
train_dataset = CIFAR10(
data_path,
True,
transforms.Compose(
[
transforms.RandomHorizontalFlip(),
transforms.RandAugment(),
]
),
download=True,
)
eval_dataset = CIFAR10(
data_path,
False,
download=True,
)
train_data_loader = data.DataLoader(
train_dataset,
batch_size=train_batch_size,
sampler=data.RandomSampler(train_dataset),
num_workers=8,
collate_fn=collate_fn,
pin_memory=True,
)
eval_data_loader = data.DataLoader(
eval_dataset,
batch_size=eval_batch_size,
sampler=data.SequentialSampler(eval_dataset),
num_workers=8,
collate_fn=collate_fn,
pin_memory=True,
)
return train_data_loader, eval_data_loader
# 对浮点模型做必要的改造
class FxQATReadyMobileNetV2(MobileNetV2):
def __init__(
self,
num_classes: int = 10,
width_mult: float = 1.0,
inverted_residual_setting: Optional[List[List[int]]] = None,
round_nearest: int = 8,
):
super().__init__(
num_classes, width_mult, inverted_residual_setting, round_nearest
)
self.quant = QuantStub(scale=1 / 128)
self.dequant = DeQuantStub()
self.classifier = nn.Sequential(
nn.Dropout(p=0.2),
nn.Conv2d(self.last_channel, num_classes, kernel_size=1),
)
def forward(self, x: Tensor) -> Tensor:
x = self.quant(x)
x = self.features(x)
x = self.classifier(x)
x = self.dequant(x)
return x
if not os.path.exists(model_path):
os.makedirs(model_path, exist_ok=True)
# 浮点模型初始化
float_model = FxQATReadyMobileNetV2()
# 准备数据集
train_data_loader, eval_data_loader = prepare_data_loaders(
data_path, train_batch_size, eval_batch_size
)
# 由于模型的最后一层和预训练模型不一致,需要进行浮点 finetune
optimizer = torch.optim.Adam(
float_model.parameters(), lr=0.001, weight_decay=1e-3
)
best_acc = 0
for nepoch in range(epoch_num):
float_model.train()
train_one_epoch(
float_model,
nn.CrossEntropyLoss(),
optimizer,
None,
train_data_loader,
device,
)
# 浮点精度测试
float_model.eval()
top1, top5 = evaluate(float_model, eval_data_loader, device)
print(
"Float Epoch {}: evaluation Acc@1 {:.3f} Acc@5 {:.3f}".format(
nepoch, top1.avg, top5.avg
)
)
if top1.avg > best_acc:
best_acc = top1.avg
# 保存最佳浮点模型参数
torch.save(
float_model.state_dict(),
os.path.join(model_path, "float-checkpoint.ckpt"),
)
Files already downloaded and verified
Files already downloaded and verified
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 2.158 Acc@1 19.574 Acc@5 68.712
........................................
Float Epoch 0: evaluation Acc@1 30.270 Acc@5 84.650
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.855 Acc@1 31.136 Acc@5 82.658
........................................
Float Epoch 1: evaluation Acc@1 40.310 Acc@5 89.640
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.693 Acc@1 37.250 Acc@5 87.292
........................................
Float Epoch 2: evaluation Acc@1 46.500 Acc@5 92.000
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.596 Acc@1 41.956 Acc@5 89.068
........................................
Float Epoch 3: evaluation Acc@1 48.400 Acc@5 92.650
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.520 Acc@1 44.974 Acc@5 90.322
........................................
Float Epoch 4: evaluation Acc@1 52.620 Acc@5 93.360
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.441 Acc@1 48.216 Acc@5 91.434
........................................
Float Epoch 5: evaluation Acc@1 52.830 Acc@5 94.530
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.375 Acc@1 50.826 Acc@5 92.428
........................................
Float Epoch 6: evaluation Acc@1 55.520 Acc@5 94.200
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.309 Acc@1 53.374 Acc@5 93.236
........................................
Float Epoch 7: evaluation Acc@1 59.090 Acc@5 94.890
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.242 Acc@1 55.954 Acc@5 93.998
........................................
Float Epoch 8: evaluation Acc@1 61.350 Acc@5 95.700
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.194 Acc@1 57.872 Acc@5 94.438
........................................
Float Epoch 9: evaluation Acc@1 63.760 Acc@5 95.770
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.139 Acc@1 59.822 Acc@5 95.006
........................................
Float Epoch 10: evaluation Acc@1 65.040 Acc@5 96.500
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.102 Acc@1 61.370 Acc@5 95.460
........................................
Float Epoch 11: evaluation Acc@1 65.380 Acc@5 96.810
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.050 Acc@1 63.342 Acc@5 95.866
........................................
Float Epoch 12: evaluation Acc@1 66.690 Acc@5 96.800
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 1.011 Acc@1 64.598 Acc@5 96.196
........................................
Float Epoch 13: evaluation Acc@1 68.590 Acc@5 97.400
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.971 Acc@1 66.210 Acc@5 96.538
........................................
Float Epoch 14: evaluation Acc@1 70.600 Acc@5 97.740
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.947 Acc@1 66.918 Acc@5 96.802
........................................
Float Epoch 15: evaluation Acc@1 70.880 Acc@5 97.730
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.921 Acc@1 67.956 Acc@5 96.968
........................................
Float Epoch 16: evaluation Acc@1 71.120 Acc@5 98.160
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.895 Acc@1 68.772 Acc@5 97.086
........................................
Float Epoch 17: evaluation Acc@1 72.020 Acc@5 98.100
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.869 Acc@1 69.940 Acc@5 97.418
........................................
Float Epoch 18: evaluation Acc@1 73.200 Acc@5 98.020
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.854 Acc@1 70.526 Acc@5 97.246
........................................
Float Epoch 19: evaluation Acc@1 73.880 Acc@5 98.240
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.833 Acc@1 71.100 Acc@5 97.536
........................................
Float Epoch 20: evaluation Acc@1 74.050 Acc@5 98.020
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.816 Acc@1 71.678 Acc@5 97.626
........................................
Float Epoch 21: evaluation Acc@1 75.100 Acc@5 98.480
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.801 Acc@1 72.128 Acc@5 97.640
........................................
Float Epoch 22: evaluation Acc@1 74.070 Acc@5 98.330
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.787 Acc@1 72.822 Acc@5 97.758
........................................
Float Epoch 23: evaluation Acc@1 74.540 Acc@5 98.460
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.777 Acc@1 73.058 Acc@5 97.976
........................................
Float Epoch 24: evaluation Acc@1 76.750 Acc@5 98.580
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.758 Acc@1 73.872 Acc@5 98.018
........................................
Float Epoch 25: evaluation Acc@1 77.450 Acc@5 98.670
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.742 Acc@1 74.290 Acc@5 98.122
........................................
Float Epoch 26: evaluation Acc@1 76.680 Acc@5 98.690
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.735 Acc@1 74.576 Acc@5 98.070
........................................
Float Epoch 27: evaluation Acc@1 77.240 Acc@5 98.670
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.726 Acc@1 74.850 Acc@5 98.038
........................................
Float Epoch 28: evaluation Acc@1 76.070 Acc@5 98.610
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.722 Acc@1 75.058 Acc@5 98.132
........................................
Float Epoch 29: evaluation Acc@1 75.940 Acc@5 98.030
7.3.3. Calibration¶
模型改造完成并完成浮点训练后,便可进行 Calibration。此过程通过在模型中插入 Observer 的方式,在 forward 过程中统计各处的数据分布情况,从而计算出合理的量化参数:
对于部分模型,仅通过 Calibration 便可使精度达到要求,不必进行比较耗时的量化感知训练。
即使模型经过量化校准后无法满足精度要求,此过程也可降低后续量化感知训练的难度,缩短训练时间,提升最终的训练精度。
[4]:
######################################################################
# 用户可根据需要修改以下参数
# 1. Calibration 时使用的 batch_size
calib_batch_size = 256
# 2. Validation 时使用的 batch_size
eval_batch_size = 256
# 3. Calibration 使用的数据量,配置为 inf 以使用全部数据
num_examples = float("inf")
# 4. 目标硬件平台的代号,此处使用 bayes 举例,实际使用时需要根据实际部署平台做相应替换
march = March.BAYES
######################################################################
# 在进行模型转化前,必须设置好模型将要执行的硬件平台
set_march(march)
# 将模型转化为 Calibration 状态,以统计各处数据的数值分布特征
calib_model = prepare_qat_fx(
# 输出模型会共享输入模型的 attributes,为不影响 float_model 的后续使用,
# 此处进行了 deepcopy
copy.deepcopy(float_model),
{
"": default_calib_8bit_fake_quant_qconfig,
"module_name": {
# 在模型的输出层为 Conv 或 Linear 时,可以使用 out_qconfig
# 配置为高精度输出
"classifier": default_calib_8bit_weight_32bit_out_fake_quant_qconfig,
},
},
).to(
device
) # prepare_qat_fx 接口不保证输出模型的 device 和输入模型完全一致
# 准备数据集
calib_data_loader, eval_data_loader = prepare_data_loaders(
data_path, calib_batch_size, eval_batch_size
)
# 执行 Calibration 过程(不需要 backward)
# 注意此处对模型状态的控制,模型需要处于 eval 状态以使 Bn 的行为符合要求
calib_model.eval()
set_fake_quantize(calib_model, FakeQuantState.CALIBRATION)
with torch.no_grad():
cnt = 0
for image, target in calib_data_loader:
image, target = image.to(device), target.to(device)
calib_model(image)
print(".", end="", flush=True)
cnt += image.size(0)
if cnt >= num_examples:
break
print()
# 测试伪量化精度
# 注意此处对模型状态的控制
calib_model.eval()
set_fake_quantize(calib_model, FakeQuantState.VALIDATION)
top1, top5 = evaluate(
calib_model,
eval_data_loader,
device,
)
print(
"Calibration: evaluation Acc@1 {:.3f} Acc@5 {:.3f}".format(
top1.avg, top5.avg
)
)
# 保存 Calibration 模型参数
torch.save(
calib_model.state_dict(),
os.path.join(model_path, "calib-checkpoint.ckpt"),
)
Files already downloaded and verified
Files already downloaded and verified
....................................................................................................................................................................................................
........................................
Calibration: evaluation Acc@1 76.190 Acc@5 98.180
模型经过 Calibration 后的量化精度若已满足要求,便可直接进行转定点模型的步骤,否则需要进行量化感知训练进一步提升精度。
7.3.4. 量化感知训练¶
量化感知训练通过在模型中插入伪量化节点的方式,在训练过程中使模型感知到量化带来的影响,在这种情况下对模型参数进行微调,以提升量化后的精度。
[5]:
######################################################################
# 用户可根据需要修改以下参数
# 1. 训练时使用的 batch_size
train_batch_size = 256
# 2. Validation 时使用的 batch_size
eval_batch_size = 256
# 3. 训练的 epoch 数
epoch_num = 3
######################################################################
# 准备数据集
train_data_loader, eval_data_loader = prepare_data_loaders(
data_path, train_batch_size, eval_batch_size
)
# 将模型转为 QAT 状态
qat_model = prepare_qat_fx(
copy.deepcopy(float_model),
{
"": default_qat_8bit_fake_quant_qconfig,
"module_name": {
"classifier": default_qat_8bit_weight_32bit_out_fake_quant_qconfig,
},
},
).to(device)
# 加载 Calibration 模型中的量化参数
qat_model.load_state_dict(calib_model.state_dict())
# 进行量化感知训练
# 作为一个 filetune 过程,量化感知训练一般需要设定较小的学习率
optimizer = torch.optim.Adam(
qat_model.parameters(), lr=1e-3, weight_decay=1e-4
)
best_acc = 0
for nepoch in range(epoch_num):
# 注意此处对 QAT 模型 training 状态的控制方法
qat_model.train()
set_fake_quantize(qat_model, FakeQuantState.QAT)
train_one_epoch(
qat_model,
nn.CrossEntropyLoss(),
optimizer,
None,
train_data_loader,
device,
)
# 注意此处对 QAT 模型 eval 状态的控制方法
qat_model.eval()
set_fake_quantize(qat_model, FakeQuantState.VALIDATION)
top1, top5 = evaluate(
qat_model,
eval_data_loader,
device,
)
print(
"QAT Epoch {}: evaluation Acc@1 {:.3f} Acc@5 {:.3f}".format(
nepoch, top1.avg, top5.avg
)
)
if top1.avg > best_acc:
best_acc = top1.avg
torch.save(
qat_model.state_dict(),
os.path.join(model_path, "qat-checkpoint.ckpt"),
)
Files already downloaded and verified
Files already downloaded and verified
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.770 Acc@1 73.462 Acc@5 97.816
........................................
QAT Epoch 0: evaluation Acc@1 77.620 Acc@5 98.310
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.737 Acc@1 74.494 Acc@5 98.016
........................................
QAT Epoch 1: evaluation Acc@1 76.590 Acc@5 98.370
....................................................................................................................................................................................................
Full cifar-10 train set: Loss 0.732 Acc@1 74.830 Acc@5 98.066
........................................
QAT Epoch 2: evaluation Acc@1 77.950 Acc@5 98.480
7.3.5. 转定点模型¶
伪量化精度达标后,便可将模型转为定点模型。一般认为定点模型的结果和编译后模型的结果是完全一致的。
注意
定点模型和伪量化模型之间无法做到完全数值一致,所以请以定点模型的精度为准。若定点精度不达标,需要继续进行量化感知训练。
[6]:
######################################################################
# 用户可根据需要修改以下参数
# 1. 使用哪个模型作为流程的输入,可以选择 calib_model 或 qat_model
base_model = qat_model
######################################################################
# 将模型转为定点状态
quantized_model = convert_fx(base_model).to(device)
# 测试定点模型精度
top1, top5 = evaluate(
quantized_model,
eval_data_loader,
device,
)
print(
"Quantized model: evaluation Acc@1 {:.3f} Acc@5 {:.3f}".format(
top1.avg, top5.avg
)
)
........................................
Quantized model: evaluation Acc@1 78.000 Acc@5 98.480
7.3.6. 模型部署¶
测试定点模型精度并确认符合要求后,便可以进行模型部署的相关流程,包括模型检查、编译、性能测试和可视化。
注意
也可以跳过 Calibration 和量化感知训练中的实际校准和训练过程,先直接进行模型检查,以保证模型中不存在无法编译的操作。
由于编译器只支持 CPU,因此模型和数据必须放在 CPU 上。
[7]:
######################################################################
# 用户可根据需要修改以下参数
# 1. 编译时启用的优化等级,可选 0~3,等级越高编译出的模型上板执行速度越快,
# 但编译过程会慢
compile_opt = "O1"
######################################################################
# 这里的 example_input 也可以是随机生成的数据,但是推荐使用真实数据,以提高
# 性能测试的准确性
example_input = next(iter(eval_data_loader))[0]
example_input = example_input[0].unsqueeze(dim=0)
# 通过 trace 将模型序列化并生成计算图,注意模型和数据要放在 CPU 上
script_model = torch.jit.trace(quantized_model.cpu(), example_input)
torch.jit.save(script_model, os.path.join(model_path, "int_model.pt"))
# 模型检查
check_model(script_model, [example_input])
torch.Size([1, 3, 32, 32])
/home/users/yushu.gao/horizon/qat_docs/horizon_plugin_pytorch/qtensor.py:1178: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if scale is not None and scale.numel() > 1:
/home/users/yushu.gao/horizon/qat_docs/horizon_plugin_pytorch/nn/quantized/conv2d.py:290: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
per_channel_axis=-1 if self.out_scale.numel() == 1 else 1,
This model is supported!
HBDK model check PASS
[7]:
0
[8]:
# 模型编译,生成的 hbm 文件即为可部署的模型
ret = compile_model(
script_model,
[example_input],
hbm=os.path.join(model_path, "model.hbm"),
input_source="pyramid",
opt=compile_opt,
)
INFO: launch 16 threads for optimization
[==================================================] 100%
WARNING: arg0 can not be assigned to NCHW_NATIVE layout because it's input source is pyramid/resizer.
consumed time 0.655841
HBDK model compilation SUCCESS
[9]:
# 模型性能测试
ret = perf_model(
script_model,
[example_input],
out_dir=os.path.join(model_path, "perf_out"),
input_source="pyramid",
opt=compile_opt,
layer_details=True,
)
INFO: launch 16 threads for optimization
[==================================================] 100%
WARNING: arg0 can not be assigned to NCHW_NATIVE layout because it's input source is pyramid/resizer.
consumed time 0.587685
HBDK model compilation SUCCESS
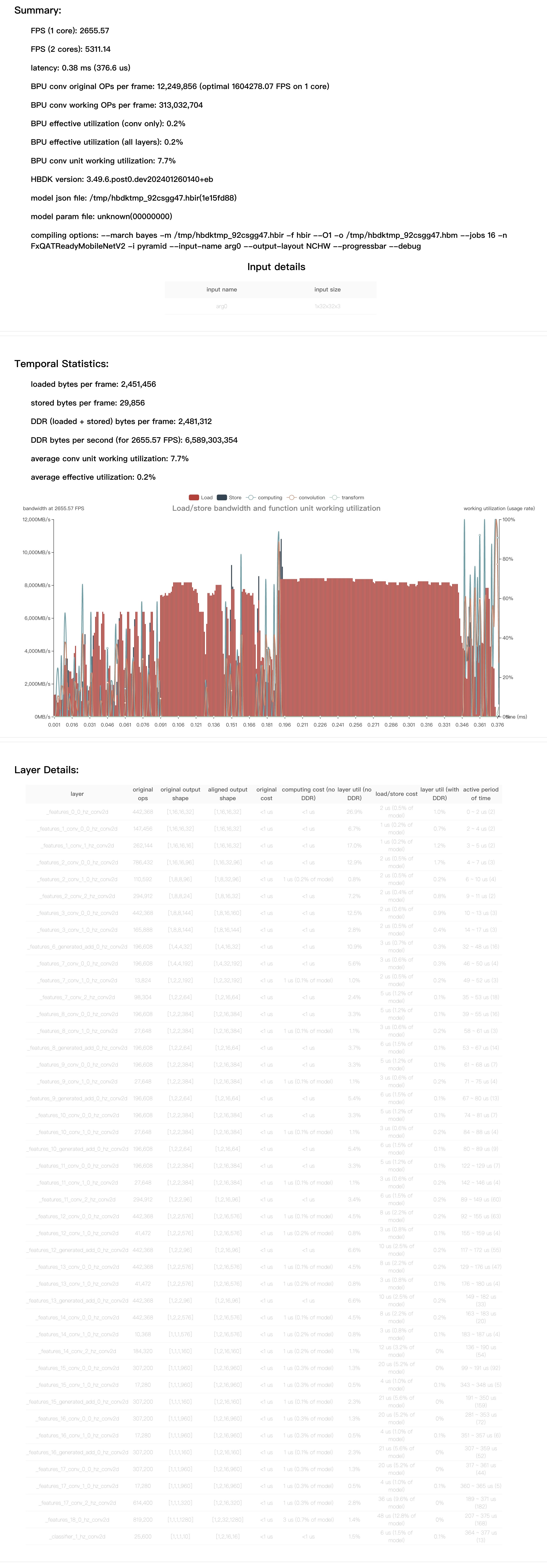
FPS=2655.57, latency = 376.6 us, DDR = 2481312 bytes (see model/mobilenetv2/perf_out/FxQATReadyMobileNetV2.html)
HBDK model compilation SUCCESS
HBDK performance estimation SUCCESS
根据提示,找到性能结果文件,内容如下:
[10]:
# 模型可视化
visualize_model(
script_model,
[example_input],
save_path=os.path.join(model_path, "model.svg"),
show=False,
)
INFO: launch 1 threads for optimization
consumed time 0.424022
HBDK model compilation SUCCESS