4.1.1.7. 模型性能分析与调优¶
本节介绍了如何使用地平线提供的工具评估模型性能。 如果此阶段发现评估结果不符合预期,强烈建议您尽量在此阶段根据地平线的优化建议解决性能问题, 不建议将模型的问题延伸到应用开发阶段。
4.1.1.7.1. 使用 hb_perf 工具估计性能¶
地平线提供的 hb_perf 以模型转换得到的 ***.bin为输入,可以直接得到模型预期上板性能(不含CPU部分的计算评估),工具使用方式如下:
hb_perf ***.bin
注解
如果分析的是 pack 后模型,需要加上一个 -p 参数,命令为 hb_perf -p ***.bin。
关于模型 pack,请查看 其他模型工具(可选) 部分的介绍。
命令中的 ***.bin就是模型转换产出的bin模型,命令执行完成后,
在当前工作目录下会得到一个 hb_perf_result 目录,分析结果以html形式提供。
以下是我们分析一个MobileNet的示例结果,其中mobilenetv1_224x224_nv12.html就是查看分析结果的主页面。
hb_perf_result/
└── mobilenetv1_224x224_nv12
├── MOBILENET_subgraph_0.html
├── MOBILENET_subgraph_0.json
├── mobilenetv1_224x224_nv12
├── mobilenetv1_224x224_nv12.html
├── mobilenetv1_224x224_nv12.png
└── temp.hbm
通过浏览器打开结果主页面,其内容如下图:

分析结果主要由Model Performance Summary、Details和BIN Model Structure三个部分组成。 Model Performance Summary是整个bin模型的整体性能评估结果,其中各项指标为:
Model Name——模型名称。
BPU Model Latency(ms)——模型整体单帧计算耗时(单位为ms)。
Total DDR (loaded+stored) bytes per frame(MB per frame)——模型整体BPU部分数据加载和存储所占用的DDR总量(单位为MB/frame)。
Loaded Bytes per Frame——模型运行每帧读取数据量。
Stored Bytes per Frame——模型运行每帧存储数据量。
在了解Details和BIN Model Structure前,您需要了解子图(subgraph)的概念。 如果模型在非输入和输出部分出现了CPU计算的算子,模型转换工具将把这个算子前后连续在BPU计算的部分拆分为两个独立的子图(subgraph)。 具体可以参考 验证模型 部分的介绍。
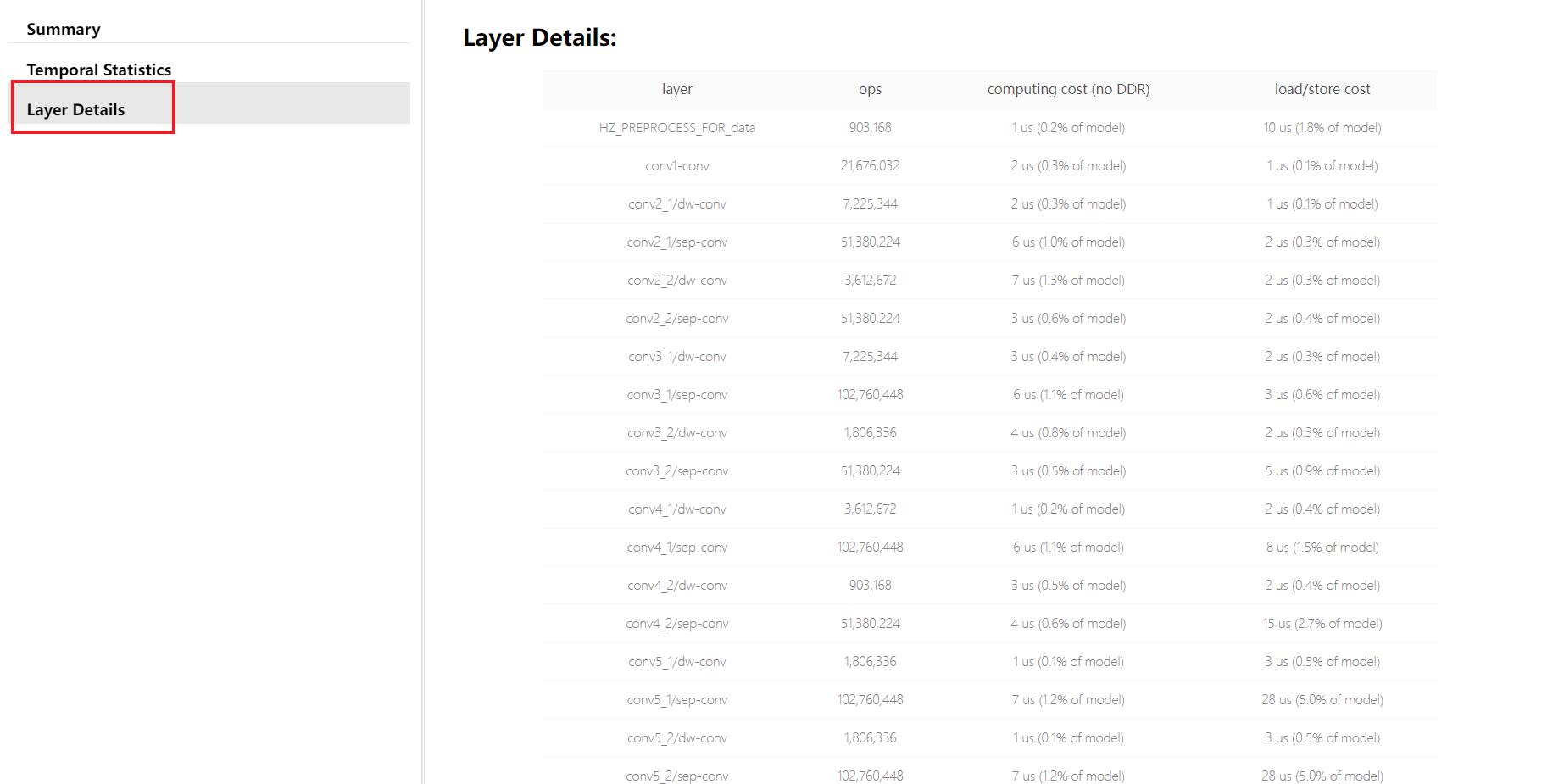
Details是每份模型BPU子图的具体信息,在主页面中,每个子图提供的指标解读如下:
Model Subgraph Name——子图名称。
Model Subgraph Calculation Load (OPpf)——子图的单帧计算量。
Model Subgraph DDR Occupation(Mbpf)——子图的单帧读写数据量(单位为MB)。
Model Subgraph Latency(ms)——子图的单帧计算耗时(单位为ms)。
每份子图结果提供了一个明细入口,以上指标都是明细页面提取到的,进入到明细页面可以给您更加细致的参考信息。
注意
需要特别注意的是,明细页面会根据您是否启用调试参数( debug )而有所区别,
下图中的Layer Details仅当在配置文件中设置 debug 参数为 True 时才可以拿到,
这个 debug 参数配置方法请参考 使用 hb_mapper makertbin 工具转换模型 部分的介绍。
Layer Details提供到了具体算子级别的分析,在调试分析阶段也是比较不错的参考, 如果是某些BPU算子导致性能低,可以帮助您定位到这个具体算子。
BIN Model Structure部分提供的是bin模型的子图级可视化结果,图中深色节点表示运行在BPU上的节点,灰色节点表示在CPU上计算的节点。
使用 hb_perf 的意义在于了解bin模型子图结构,对于BPU上计算部分,该工具也能提供较全面的静态分析指标。
不过 hb_perf 不含CPU部分的计算评估,如果CPU计算仅限于模型输入或输出部分的常规性处理,不含计算密集型计算节点,这个影响不大。
否则,您就一定需要利用开发板工具实测性能。
4.1.1.7.2. 开发板实测性能¶
开发板上实测模型性能使用的是开发板上 hrt_model_exec perf 工具,
hrt _model_exec 是一个模型执行工具,可直接在开发板上评测模型的推理性能、获取模型信息。
一方面可以让用户拿到模型时实际了解模型真实性能;
另一方面也可以帮助用户了解模型可以做到的速度极限,对于应用调优的目标极限具有指导意义。
使用 hrt_model_exec perf 工具前,有两个准备工作。
确保您已经参考 环境部署 介绍完成了开发板上工具安装。
第二是需要将Ubuntu开发机上得到的bin模型拷贝到开发板上(建议放在/userdata目录), 开发板上是一个Linux系统,可以通过
scp等Linux系统常用方式完成这个拷贝过程。
注解
此时使用的模型不需要打开debug,debug打开会影响模型在开发板的测试结果。
使用 hrt_model_exec perf 实测性能的参考命令如下(注意是在开发板上执行):
./hrt_model_exec perf --model_file mobilenetv1_224x224_nv12.bin \
--model_name="" \
--core_id=0 \
--frame_count=200 \
--perf_time=0 \
--thread_num=1 \
--profile_path="."
其中,各参数含义如下:
model_file:
需要分析性能的bin模型名称。
model_name:
需要分析性能的bin模型名字。若 model_file 只含一个模型,则可以省略。
core_id:
默认值 0,运行模型使用的核心id,0 代表任意核心,1 代表核心0,2 代表核心1。若要分析双核极限帧率,请将此处设为 0。
frame_count:
默认值 200,设置推理帧数,工具会执行指定次数后再分析平均耗时。 当 perf_time 为 0 时生效。
perf_time:
默认值 0,单位分钟。设置推理时间,工具会执行指定时间后再分析平均耗时。
thread_num:
默认值 1,设置运行的线程数,取值范围 [1,8]。若要分析极限帧率,请将线程数改大。
profile_path:
默认关闭,统计工具日志产生路径。该参数引入的分析结果会存放在指定目录下的profiler.log和profiler.csv文件中。
命令执行完成后,您将在控制台得到如下结果。
最终的评估结果就是 Average latency 和 Frame rate,分别表示平均单帧推理延时和模型极限帧率。
如果想获得模型在板子上运行的极限帧率,需将 thread_num 设置得足够大。
Running condition:
Thread number is: 1
Frame count is: 200
Program run time: 818.985000 ms
Perf result:
Frame totally latency is: 800.621155 ms
Average latency is: 4.003106 ms
Frame rate is: 244.204717 FPS
控制台得到的信息只有整体情况,通过 profile_path 控制产生的 profiler.log 和 profiler.csv 文件记录了更加丰富的信息如下:
{
"perf_result": {
"FPS": 244.20471681410527,
"average_latency": 4.003105640411377
},
"running_condition": {
"core_id": 0,
"frame_count": 200,
"model_name": "mobilenetv1_224x224_nv12",
"run_time": 818.985,
"thread_num": 1
}
}
***
{
"processor_latency": {
"BPU_inference_time_cost": {
"avg_time": 3.42556,
"max_time": 3.823,
"min_time": 3.057
},
"CPU_inference_time_cost": {
"avg_time": 0.29193,
"max_time": 0.708,
"min_time": 0.101
}
},
"model_latency": {
"BPU_MOBILENET_subgraph_0": {
"avg_time": 3.42556,
"max_time": 3.823,
"min_time": 3.057
},
"Dequantize_fc7_1_HzDequantize": {
"avg_time": 0.12307,
"max_time": 0.274,
"min_time": 0.044
},
"MOBILENET_subgraph_0_output_layout_convert": {
"avg_time": 0.025945,
"max_time": 0.069,
"min_time": 0.012
},
"Preprocess": {
"avg_time": 0.009245,
"max_time": 0.027,
"min_time": 0.003
},
"Softmax_prob": {
"avg_time": 0.13366999999999998,
"max_time": 0.338,
"min_time": 0.042
}
},
"task_latency": {
"TaskPendingTime": {
"avg_time": 0.04952,
"max_time": 0.12,
"min_time": 0.009
},
"TaskRunningTime": {
"avg_time": 3.870965,
"max_time": 4.48,
"min_time": 3.219
}
}
}
这里的内容会对应到 使用hb_perf工具估计性能 中的BIN Model Structure部分介绍的bin可视化图中,
图中每个节点都有一个对应节点在profiler.log文件中,可以通过 name 对应起来。
profiler.log 文件中记录了每个节点的执行时间,对优化节点有重要的参考意义。
由于模型中的BPU节点对输入输出有特殊要求,如特殊的layout和padding对齐要求,因此需要对BPU节点的输入、输出数据进行处理。
Preprocess:表示对模型输入数据进行padding和layout转换操作,其耗时统计在Preprocess中。xxxx_input_layout_convert: 表示对BPU节点的输入数据进行padding和layout转换的操作,其耗时统计在xxxx_input_layout_convert中。xxxx_output_layout_convert: 表示对BPU节点输出数据进行去掉padding和layout转换的操作,其耗时统计在xxxx_output_layout_convert中。
profiler 分析是经常使用的操作,前文 检查结果解读 部分提到检查阶段不用过于
关注CPU算子, 此阶段就能看到CPU算子的具体耗时情况了,如果根据这里的评估认为CPU耗时太长,那就值得优化了。
4.1.1.7.3. 模型性能优化¶
根据以上性能分析结果,您可能发现性能结果不及预期,本章节内容介绍了地平线对提升模型性能的建议与措施,包括: 检查yaml配置参数、 处理CPU算子、 高性能模型设计建议、 使用地平线平台友好结构&模型 等内容。
部分修改可能会影响原始浮点模型的参数空间,意味着需要您重训模型,为了避免性能调优过程中反复调整并训练的代价, 在得到满意性能效果前,建议您使用随机参数导出模型来验证性能即可。
检查影响模型性能的yaml参数
在模型转换的yaml配置文件中,部分参数会实际影响模型的最终性能,可以先检查下是否已正确按照预期配置,
各参数的具体含义和作用请参考 hb_mapper 工具介绍 章节中的 配置文件详细介绍 小节的内容。
layer_out_dump:指定模型转换过程中是否输出模型的中间结果,一般仅用于调试功能。 如果将其配置为True,则会为每个卷积算子增加一个反量化输出节点,它会显著的降低模型上板后的性能。 所以在性能评测时,务必要将该参数配置为False。compile_mode:该参数用于选择模型编译时的优化方向为带宽还是时延,关注性能时请配置为latency。optimize_level:该参数用于选择编译器的优化等级,实际生产中应配置为O3获取最佳性能。core_num:配置为2时可同时调用两个核运行,降低单帧推理延迟,但是也会影响整体的吞吐率。debug:配置为True将打开编译器的debug模式,能够输出性能仿真的相关信息,如帧率、DDR 带宽占用等。 一般用于性能评估阶段。可关闭该参数减小模型大小,提高模型执行效率。max_time_per_fc:该参数用于控制编译后的模型数据指令的function-call的执行时长,从而实现模型优先级抢占功能。 设置此参数更改被抢占模型的function-call执行时长会影响该模型的上板性能。
处理CPU算子
根据 hrt_model_exec perf 的评估,已经确认突出的性能瓶颈是CPU算子导致的。
此种情况下,我们建议您先查看 模型转换工具链算子支持约束列表 章节,确认当前运行在CPU上的算子是否具备BPU支持的能力。
如果算子不具备BPU支持能力,那么就是您的算子参数超过了BPU支持的参数约束范围, 将相应原始浮点模型计算参数调整到约束范围内即可。 为了方便您快速知晓超出约束的具体参数,建议您再使用 验证模型 部分介绍的方法做一遍检查, 工具将会直接给出超出BPU支持范围的参数提示。
注解
修改原始浮点模型参数对模型计算精度的影响需要您自己把控,
例如Convolution的 input_channel 或 output_channel 超出范围就是一种较典型的情况,
减少channel快速使得该算子被BPU支持,单单只做这一处修改也预计会对模型精度产生影响。
如果算子并不具备BPU支持能力,就需要您根据以下情况做出对应优化操作:
CPU 算子处于模型中部
对于CPU 算子处于模型中部的情况,建议您优先尝试参数调整、算子替换或修改模型。
CPU算子处于模型首尾部
对于CPU算子处于模型首尾部的情况,请参考以下示例,下面以量化/反量化节点为例:
对于与模型输入输出相连的节点,可以在yaml文件model_parameters配置组(模型参数组)中增加
remove_node_type参数,并重新编译模型。remove_node_type: "Quantize; Dequantize"
或使用hb_model_modifier 工具对bin模型进行修改:
hb_model_modifier x.bin -a Quantize -a Dequantize
对于下图这种没有与输入输出节点相连的模型,则需要使用hb_model_modifier工具判断相连节点是否支持删除后按照顺序逐个进行删除。
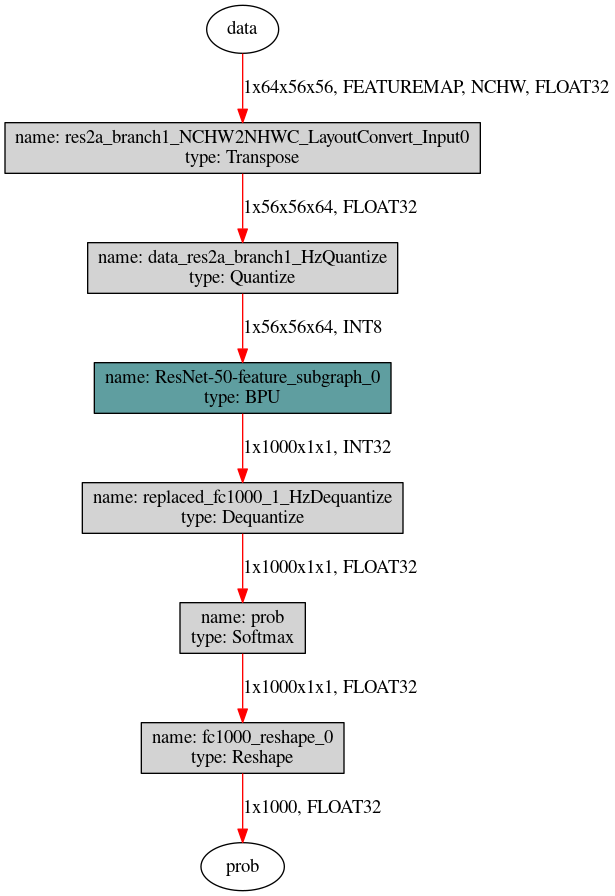
先使用hb_perf工具获取模型结构图片,然后使用以下两条命令可以自上而下移除Quantize节点, 对于Dequantize节点自下而上逐个删除即可,每一步可删除节点的名称可以通过
hb_model_modifier x.bin进行查看。hb_model_modifier x.bin -r res2a_branch1_NCHW2NHWC_LayoutConvert_Input0 hb_model_modifier x_modified.bin -r data_res2a_branch1_HzQuantize
高性能模型设计建议
根据性能评估结果,CPU上耗时占比可能很小,主要的性能瓶颈还是BPU推理时间过长。 这种情况下,我们已经把计算器件都用上了,发力的空间就在于提升计算资源的利用率。 每种处理器都有自己的硬件特性,算法模型的计算参数是否很好地符合了硬件特性, 直接决定了计算资源的利用率,符合度越高则利用率越高,反之则低。 本部分介绍重点在于阐明地平线的硬件特性。 首先,地平线的计算平台旨在加速CNN(卷积神经网络),主要的计算资源都集中在处理各种卷积计算。 所以,我们希望您的模型是以卷积计算为主的模型,卷积之外的算子都会导致计算资源的利用率降低,不同OP的影响程度会有所不同。
整体硬件要求
下表是硬件层面提出的一些计算友好性要求,供您做一个全面参考。
Operators |
Restrictions |
Note |
|---|---|---|
Convolution |
Kernel HxW=[1,7]x[1,7] |
kernel size 2, 4, 6会造成算力浪费 |
Channel Num (one group) <= 2048 |
||
Conv with sumin: Stride∈{1, 2}, Others: no restriction |
|
|
必须能够被stride整除 |
Dilation会引入额外的数据搬移 |
|
Size of Kernel: HxWxC <= 32768 |
||
Deconvolution |
Kernel HxW=[2,14]x[2,14] |
Deconvolution is not natively supported by BPU. |
Channel Num <= 2048 |
||
Padding HxW=[0,(Kernel_H-1)/2]x[0,(Kernel_W-1)/2] |
||
Stride ∈ {2, 4} |
||
Fully Connected Convolution |
Kernel HxW=[1,31]x[1,31], and HxW <= 127 |
|
Channel Num∈[1,2048], or <= 16384 if H and W are both 1 |
||
for int8 output: HxCEIL(W/8)xCEIL(C/4) <= {512(X2/J2), 1024(X3J3)} |
||
for int32 output: HxCEIL(W/8)xCEIL(C/4) < {1024(X2/J2), 2048(X3J3)} |
||
Pooling |
Average pooling: Kernel HxW=[1,7]x[1,7], Stride∈{1, 2}, Padding HxW=[0,Kernel_H/2]x[0,Kernel_W/2] |
|
Global average pooling: Kernel HxW <= 8192 |
||
Max pooling: Kernel HxW=[1, 64]x[1,64], Stride=[1,256], Padding >= 0 |
Padding > 1, Stride > 2时会有额外的开销。 |
|
Global max pooling: Kernel HxW=[1,1024]x[1,1024] |
||
Upscale |
Scaling proportional range (1/256,256], precision=1/256 |
|
RoiAlign/Roiresize |
Scaling proportional range (1/256,256], precision=1/256 |
|
Channel Concat |
None |
Input feature的channel num不是4对齐的话,会比较耗时。 |
Channel Split |
Input feature channel is multiple of split number. |
Output features的channel num不是4对齐的话,会比较耗时。 |
Slice |
None |
起始坐标中的W不是8对齐的话,会比较耗时。 channel方向的slice会占用MAC计算资源。 |
Upsample |
mode={nearest}, HxWxC -> (2H)x(2W)xC |
|
Reshape |
Reshape in the H and W directions, currently N and C are not supported. |
Input/Output feature的W不是8对齐的话,会非常耗时。 |
reorder upscale: HxWxC -> (2H)x(2W)x(C/4) |
||
stack neighbor: HxWxC -> (H/2)x(W/2)x(4C) |
||
Shuffle |
Input feature channel <= 2048, only supports shuffle in C direction |
如果shuffle的粒度不是4的倍数,会占用MAC计算资源。 |
Elementwise Add |
Input feature channel <= 2048 |
会占用MAC计算资源 |
Elementwise Mul |
Input feature channel <= 2048 |
会占用MAC计算资源,而且效率较低。 |
Broadcast Mul |
Input feature channel <= 2048 |
会占用MAC计算资源,而且效率较低。 |
Elementwise Max/Min |
Input feature channel <= 2048 |
会占用MAC计算资源,而且效率较低。 |
LookupTable (sigmoid,tanh..) |
Lookup table: int8 -> int8 |
会占用MAC计算资源,而且效率较低。 |
Pad |
Pad Zero, Constant or Boundary |
|
Cross Channel Max |
Input feature channel ∈ [1, 64*group_num]. |
|
Detection Post Process |
Filter + Sort + NMS |
|
Anchor num: [1, 64], Class num: [1, 64] |
||
Max output num: 4096 |
||
Leaky Relu |
None |
会占用MAC计算资源,而且效率较低。 |
Prelu |
None |
会占用MAC计算资源,而且效率较低。 |
Relu/Relu6 |
None |
会占用MAC计算资源,而且效率较低。 |
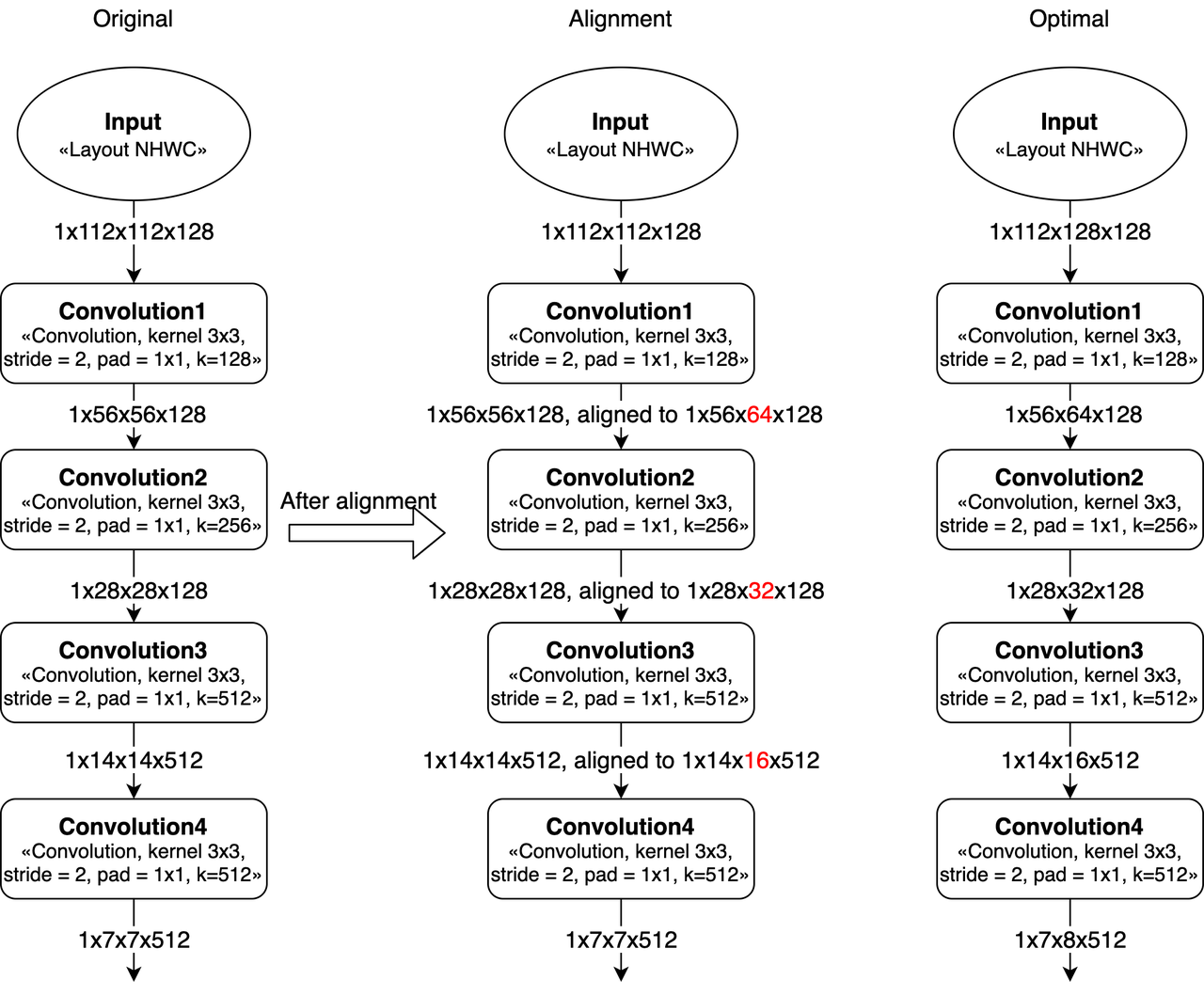
卷积的Width对齐
因为计算MAC阵列对齐要求的问题,featuremap的W在8对齐的时候效率会比较高(Convolution的stride=2时,W需要16对齐)。 如果不是8或16对齐,那么就会带来算力浪费,导致MAC利用率变低。 比如,如果convolution的输入feature大小是 1x8x9x32 (NHWC),那么在实际计算时, W会被padding到16(即feature大小变为1x8x16x32),会造成计算资源浪费。
在设计网络的时候,如果可以改变整个神经网络的输入大小(向上或向下对齐),那么模型的MAC利用率会直接提高。
模型输入大小的示例,比如一个多层stride=2 conv的网络(从resnet截取),输入224和256/192的区别。
卷积的Channel对齐
Channel在硬件上是需要8对齐的,在算法设计的时候最好将kernel num调整为8的倍数。
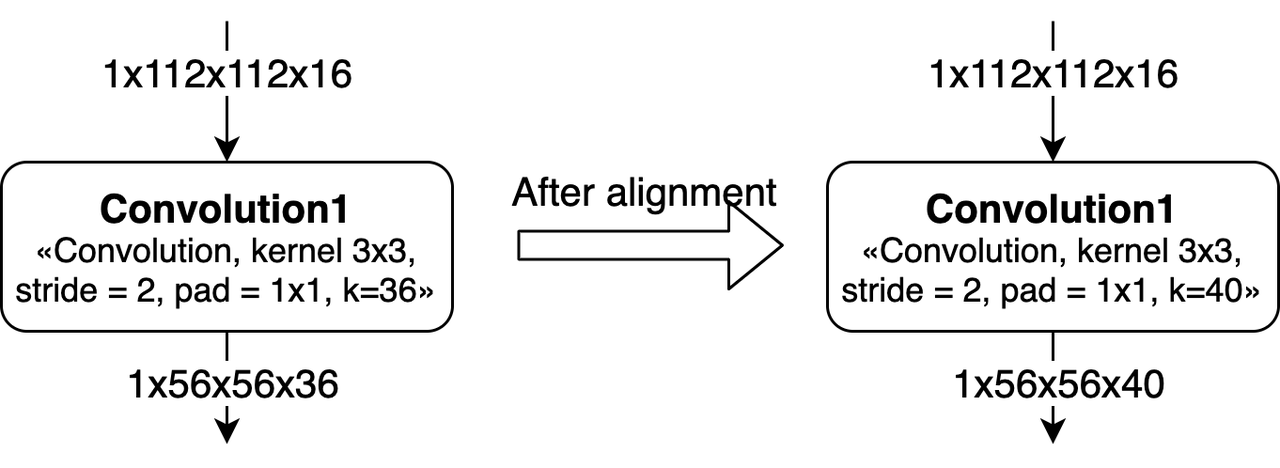
对于Group Convolution,channel的对齐情况会更加复杂一些。
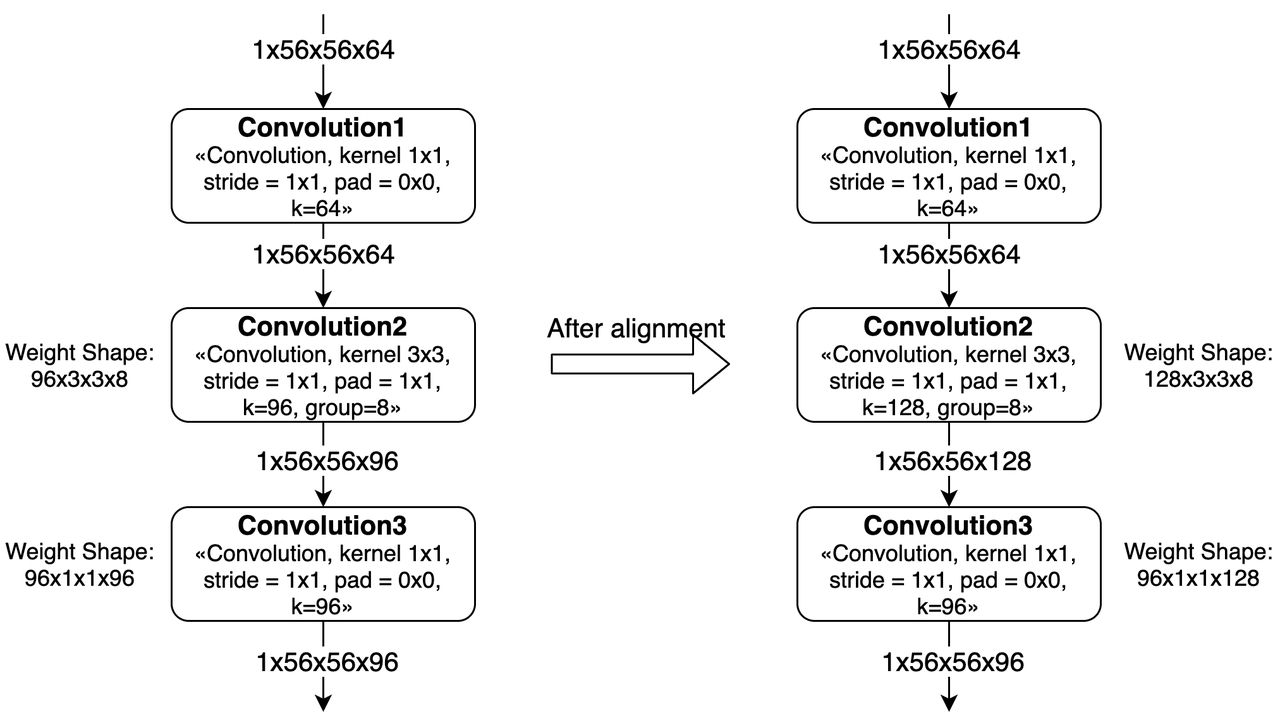
如果Kernel不是8的整数倍,那么每个group的kernel num需要对齐到8。 而且,由于这个对齐,会导致之后的convolution也产生算力浪费。 如上图所示,Convolution2中对weight进行padding之后,下一层的weight也需要进行padding。
注解
padding的方式是每个group内对齐到8,即padding的数据是分散在整个weight中间。
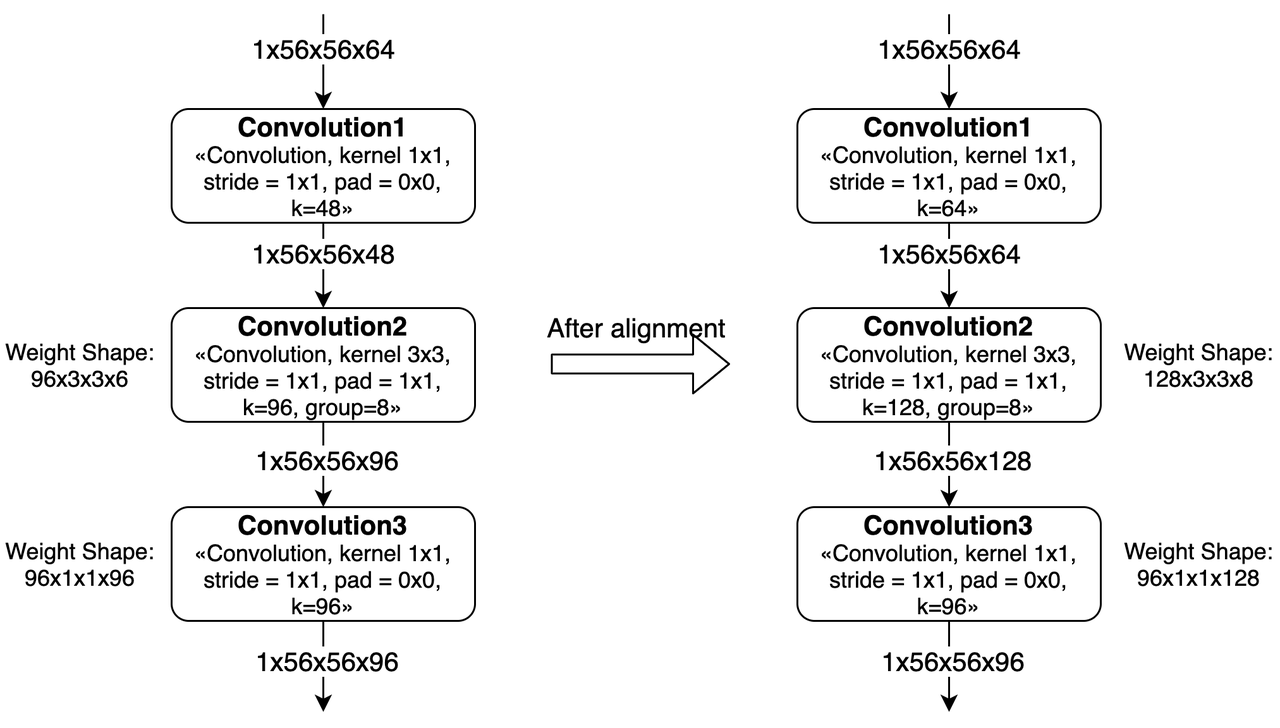
如果group内channel不是8的整数倍,那么就需要对上一层convolution进行padding。 如上图所示,Convolution1的kernel num从48被padding到了64。
另外,如果有连续多个group convolution中发生了group内kernel num或channel num不对齐的情况,那么影响会更大。 这种情况下我们需要同时考虑多层group conv的对齐要求,会导致更多的padding。 最差情况下,group convolution会被转换为普通convolution。
激活函数
大部分激活函数需要用LUT和Elementwise OP实现,虽然现在可以支持LUT和Elementwise操作,但是都是用其它OP拼出来的,而且效率都不太高。
如果模型中只有少量的几个地方使用非硬件直接支持的激活函数(非relu),而且计算量不是特别大,那么是可以使用的。 在这种情况下,对整个模型的计算效率应该不会很大。
如果模型中需要大量使用非硬件直接支持的激活函数,那么会对模型的执行速度产生非常大的影响。
其他建议
地平线计算平台上的depthwise convolution的计算效率接近100%,所以对于MobileNet类的模型,BPU具有效率优势。
另外,在模型设计时,我们应尽量让模型BPU段的输入输出维度降低,以减少量化、反量化节点的耗时和硬件的带宽压力。 以典型的分割模型为例,我们可以将Argmax算子直接合入模型本身。 但需注意,只有满足以下条件,Argmax才支持BPU加速:
Caffe中的Softmax层默认axis=1,而ArgMax层则默认axis=0,算子替换时要保持axis的一致。
Argmax的Channel需小于等于64,否则只能在CPU上计算。
BPU面向高效率模型优化
学术界在持续优化算法模型的计算效率(同样算法精度下所需的理论计算量越小越高效)、参数效率(同样算法精度下所用参数量越小越高效)。 这方面的代表工作有EfficientNet和ResNeXt,二者分别使用了Depthwise Convolution和Group Convolution。 面对这样的高效率模型,GPU/TPU支持效率很低,不能充分发挥算法效果,学术界被迫针对GPU/TPU分别优化了EfficientNet V2/X和NFNet, 优化过程主要是通过减少Depthwise Convolution的使用以及大幅扩大Group Convolution中的Group大小, 这些调整都降低了原本模型的计算效率和参数效率。
地平线X3-BPU、J3-BPU对于Depthwise Convolution和Group Convolution都有专门的优化,使得用户可以获得最高的计算效率、参数效率。
作为这两类模型的参考示例,工具链model_zoo发布物中提供:
efficientnet[-lite]系列,追求极致的计算效率、参数效率。 X3-BPU能够高效支持,以EfficientNet Lite0为例,X3-BPU帧率为某端侧30TOPS GPU帧率6倍。
vargnet系列,地平线自主设计模型,充分利用Group Convolution的高效率,同时针对X3-BPU、J3-BPU 做了优化。 在地平线的应用场景中广泛使用。对于训练超参数相对鲁棒,能够以较低的调参代价切换到不同的任务。
更多的模型结构和业务模型都在持续探索中,我们将提供更加丰富的模型给您作为直接的参考, 这些产出将不定期更新至 https://github.com/HorizonRobotics-Platform/ModelZoo/tree/master。 如果以上依然不能满足您的需要,欢迎在地平线唯一官方技术社区(https://developer.horizon.ai)发帖与我们取得联系, 我们将根据您的具体问题提供更具针对性的指导建议。