4.1.1.6. 模型量化与编译¶
转换模型阶段会完成浮点模型到地平线混合异构模型的转换,经过这个阶段,您将得到一个可以在地平线计算平台上运行的模型。 在进行转换之前,请确保已经顺利通过了 验证模型 小节的过程。
模型转换使用 hb_mapper makertbin 工具完成,转换期间会完成模型优化和校准量化等重要过程,校准需要依照模型预处理要求准备校准数据,
您可以参考 校准数据准备 章节内容对校准数据进行预先准备。
为了方便您全面了解模型转换,本节将依次介绍转换工具使用、转换内部过程解读、转换结果解读和转换产出物解读。
4.1.1.6.1. 使用hb_mapper makertbin工具转换模型¶
hb_mapper makertbin提供两种模式,开启 fast-perf 模式和不开启 fast-perf 模式。
fast-perf 模式开启后,会在转换过程中生成可以在板端运行最高性能的bin模型,工具内部主要进行以下操作:
删除模型首尾部的Quantize/Dequantize节点。
删除其他hb_model_modifier支持的CPU算子,如Transpose、Cast、Reshape算子等。
配置O3编译器优化选项。
hb_mapper makertbin命令使用方式如下:
不开启 fast-perf 模式:
hb_mapper makertbin --config ${config_file} \
--model-type ${model_type}
开启 fast-perf 模式:
hb_mapper makertbin --fast-perf --model ${caffe_model/onnx_model} --model-type ${model_type} \
--proto ${caffe_proto} \
--march ${march}
- hb_mapper makertbin的命令行参数说明:
- --help
显示帮助信息并退出。
- -c, --config
模型编译的配置文件,为yaml格式,文件名使用.yaml后缀。
- --model-type
caffe或者onnx。- --fast-perf
开启fast-perf模式,该模式开启后,会在转换过程中生成可以在板端运行最高性能的bin模型,方便您用于后续的模型性能评测。
如您开启了fast-perf模式,还需要进行如下配置:
--modelCaffe或ONNX浮点模型文件。--proto用于指定Caffe模型prototxt文件。--marchBPU的微架构。若使用X/J3系列处理器则设置为bernoulli2,若使用J5处理器则设置为bayes。
一份完整的配置文件模板如下:
注解
此处配置文件仅作展示,在实际模型配置文件中 caffe_model 与 onnx_model 两种只存在其中之一。
即,要么是Caffe模型,要么是ONNX模型。即 caffe_model + prototxt 或者 onnx_model 二选一。
# 模型参数组
model_parameters:
# 原始Caffe浮点模型描述文件
prototxt: '***.prototxt'
# 原始Caffe浮点模型数据模型文件
caffe_model: '****.caffemodel'
# 原始Onnx浮点模型文件
onnx_model: '****.onnx'
# 转换的目标处理器架构
march: 'bernoulli2'
# 模型转换输出的用于上板执行的模型文件的名称前缀
output_model_file_prefix: 'mobilenetv1'
# 模型转换输出的结果的存放目录
working_dir: './model_output_dir'
# 指定转换后混合异构模型是否保留输出各层的中间结果的能力
layer_out_dump: False
# 指定模型的输出节点
output_nodes: {OP_name}
# 批量删除某一类型的节点
remove_node_type: Dequantize
# 删除指定名称的节点
remove_node_name: {OP_name}
# 输入信息参数组
input_parameters:
# 原始浮点模型的输入节点名称
input_name: "data"
# 原始浮点模型的输入数据格式(数量/顺序与input_name一致)
input_type_train: 'bgr'
# 原始浮点模型的输入数据排布(数量/顺序与input_name一致)
input_layout_train: 'NCHW'
# 原始浮点模型的输入数据尺寸
input_shape: '1x3x224x224'
# 网络实际执行时,输入给网络的batch_size, 默认值为1
input_batch: 1
# 在模型中添加的输入数据预处理方法
norm_type: 'data_mean_and_scale'
# 预处理方法的图像减去的均值, 如果是通道均值,value之间必须用空格分隔
mean_value: '103.94 116.78 123.68'
# 预处理方法的图像缩放比例,如果是通道缩放比例,value之间必须用空格分隔
scale_value: '0.017'
# 转换后混合异构模型需要适配的输入数据格式(数量/顺序与input_name一致)
input_type_rt: 'yuv444'
# 输入数据格式的特殊制式
input_space_and_range: 'regular'
# 转换后混合异构模型需要适配的输入数据排布(数量/顺序与input_name一致),若input_type_rt配置为nv12,则此处参数不需要配置
input_layout_rt: 'NHWC'
# 校准参数组
calibration_parameters:
# 模型校准使用的标定样本的存放目录
cal_data_dir: './calibration_data'
# 指定校准数据二进制文件的数据存储类型。
cal_data_type: 'float32'
# 开启图片校准样本自动处理(skimage read; resize到输入节点尺寸)
#preprocess_on: False
# 校准使用的算法类型
calibration_type: 'kl'
# max 校准方式的参数
max_percentile: 1.0
# 强制指定OP在CPU上运行
run_on_cpu: {OP_name}
# 强制指定OP在BPU上运行
run_on_bpu: {OP_name}
# 指定是否针对每个channel进行校准
per_channel: False
# 指定输出节点的数据精度
optimization: set_model_output_int8
# 编译参数组
compiler_parameters:
# 编译策略选择
compile_mode: 'latency'
# 是否打开编译的debug信息
debug: False
# 模型运行核心数
core_num: 1
# 模型编译的优化等级选择
optimize_level: 'O2'
# 指定名称为data的输入数据来源
input_source: {"data": "pyramid"}
# 指定模型的每个function call的最大可连续执行时间
max_time_per_fc: 1000
# 指定编译模型时的进程数
jobs: 8
# 自定义算子参数组
custom_op:
# 自定义op的校准方式
custom_op_method: register
# 自定义OP的实现文件, 该文件可由模板生成, 详情见自定义OP相关文档
op_register_files: sample_custom.py
# 自定义OP实现文件所在的文件夹, 请使用相对路径
custom_op_dir: ./custom_op
配置文件主要包含模型参数组、输入信息参数组、校准参数组、编译参数组和自定义算子参数组。 在您的配置文件中,每个参数组位置都需要存在,具体参数分为可选和必选,可选参数可以不配置。
以下是具体参数信息,参数会比较多,我们依照上述的参数组次序介绍。
4.1.1.6.1.1. 配置文件具体参数信息¶
🛠️ 模型参数组
编 号 |
参数名称 |
参数配置说明 |
可选/ 必选 |
|---|---|---|---|
1 |
|
参数作用:指定Caffe浮点模型的prototxt文件名称。 取值范围:无。 默认配置:无。 参数说明:在 |
可选 |
2 |
|
参数作用:指定Caffe浮点模型的caffemodel文件名称。 取值范围:无。 默认配置:无。 参数说明:在 |
可选 |
3 |
|
参数作用:指定ONNX浮点模型的onnx文件名称。 取值范围:无。 默认配置:无。 参数说明:在 |
可选 |
4 |
|
参数作用:指定产出混合异构模型需要支持的平台架构。 取值范围: 默认配置: 无。 参数说明: 两个可选配置值依次对应X3&J3和J5处理器, 根据您使用的平台选择。 |
必选 |
5 |
|
参数作用:指定转换产出混合异构模型的名称前缀。 取值范围:无。 默认配置: 参数说明:输出的定点模型文件的名称前缀。 |
可选 |
6 |
|
参数作用:指定模型转换输出的结果的存放目录。 取值范围:无。 默认配置: 参数说明:若该目录不存在,则工具会自动创建目录。 |
可选 |
7 |
|
参数作用:指定混合异构模型是否保留输出中间层值的能力。 取值范围: 默认配置: 参数说明:输出中间层的值是调试需要用到的手段, 常规状态下请不要开启。 |
可选 |
8 |
|
参数作用:指定模型的输出节点。 取值范围:无。 默认配置:无。 参数说明:一般情况下,转换工具会自动识别模型的输出节点。 此参数用于支持您指定一些中间层次作为输出。 设置值为模型中的具体节点名称, 多个值的配置方法请参考 param_value配置。 需要您注意的是,一旦设置此参数后,工具将不再自动识别输出节点, 您通过此参数指定的节点就是全部的输出。 |
可选 |
9 |
|
参数作用:设置删除节点的类型。 取值范围:”Quantize”, “Transpose”, “Dequantize”, “Cast”, “Reshape”, “Softmax”。不同类型用”;”分割。 默认配置:无。 参数说明:该参数为隐藏参数, 不设置或设置为空不影响模型转换过程。 此参数用于支持您设置待删除节点的类型信息。 被删除的节点必须在模型的开头或者末尾, 与模型的输入或输出连接。 注意:待删除节点会按顺序依次删除,并动态更新模型结构; 同时在节点删除前还会判断该节点是否位于模型的输入输出处。 因此节点的删除顺序很重要。 |
可选 |
10 |
|
参数作用:设置删除节点的名称。 取值范围:无。不同名称用”;”分割。 默认配置:无。 参数说明:该参数为隐藏参数, 不设置或设置为空不影响模型转换过程。 此参数用于支持您设置待删除节点的名称。 被删除的节点必须在模型的开头或者末尾, 与模型的输入或输出连接。 注意:待删除节点会按顺序依次删除,并动态更新模型结构; 同时在节点删除前还会判断该节点是否位于模型的输入输出处。 因此节点的删除顺序很重要。 |
可选 |
11 |
|
参数作用:保存用于精度debug分析的校准数据。 取值范围: 默认配置:无。 参数说明:该参数作用为保存用于精度debug分析的校准数据,数据格式为.npy。 该数据通过np.load()可直接送入模型进行推理。 若不设置此参数,您也可自行保存数据并使用精度debug工具进行精度分析。 |
可选 |
🛠️ 输入信息参数组
编 号 |
参数名称 |
参数配置说明 |
可选/ 必选 |
|---|---|---|---|
1 |
|
参数作用:指定原始浮点模型的输入节点名称。 取值范围:无。 默认配置:无。 参数说明:浮点模型只有一个输入节点情况时不需要配置, 多于一个输入节点时必须配置以保证后续类型及校准数据输入顺序的准确性。 多个值的配置方法请参考 param_value配置。 |
可选 |
2 |
|
参数作用:指定原始浮点模型的输入数据类型。 取值范围: 默认配置:无。 参数说明:每一个输入节点都需要配置一个确定的输入数据类型,
存在多个输入节点时,设置的节点顺序需要与
多个值的配置方法请参考 param_value配置。 数据类型的选择请参考: 转换内部过程解读 部分的介绍。 |
必选 |
3 |
|
参数作用:指定原始浮点模型的输入数据排布。 取值范围: 默认配置:无。 参数说明:每一个输入节点都需要配置一个确定的输入数据排布,
这个排布必须与原始浮点模型所采用的数据排布相同。存在多个输入节点时,
设置的节点顺序需要与 多个值的配置方法请参考 param_value配置。 什么是数据排布请参考: 转换内部过程解读 部分的介绍。 |
必选 |
4 |
|
参数作用:转换后混合异构模型需要适配的输入数据格式。 取值范围:
默认配置:无。 参数说明:这里是指明您需要使用的数据格式。 不要求与原始模型的数据格式一致。 但是需要注意在边缘平台喂给模型的数据是使用这个格式。 每一个输入节点都需要配置一个确定的输入数据类型,存在多个输入节点时,
设置的节点顺序需要与 多个值的配置方法请参考 param_value配置。 数据类型的选择请参考: 转换内部过程解读 部分的介绍。 |
必选 |
5 |
|
参数作用:转换后混合异构模型需要适配的输入数据排布。 取值范围: 默认配置:无。 参数说明:每一个输入节点都需要配置一个确定的输入数据排布。 这个输入是您希望给混合异构模型指定的排布。 不合适的输入数据的排布设置将会影响性能,
存在多个输入节点时,设置的节点顺序需要与
多个值的配置方法请参考 param_value配置。 什么是数据排布请参考: 转换内部过程解读 部分的介绍。 |
可选 |
6 |
|
参数作用:指定输入数据格式的特殊制式。 取值范围: 默认配置: 参数说明:这个参数是为了适配不同ISP输出的yuv420格式,
在相应
更多信息可以通过网络资料了解bt601。 在没有明确需要的情况下,您不要配置此参数。 |
可选 |
7 |
|
参数作用:指定原始浮点模型的输入数据尺寸。 取值范围:无。 默认配置:无。 参数说明:shape的几个维度以 原始浮点模型只有一个输入节点情况时可以不配置, 工具会自动读取模型文件中的尺寸信息。 配置多个输入节点时,设置的节点顺序需要与 多个值的配置方法请参考 param_value配置。 |
可选 |
8 |
|
参数作用:指定转换后混合异构模型需要适配的输入batch数量。 取值范围: 默认配置: 参数说明:这里input_batch为转换后混合异构bin模型输入batch数量, 但不影响转换后onnx的模型的输入batch数量。 此参数不配置时默认为1。 此参数仅在单输入且 |
可选 |
9 |
|
参数作用:在模型中添加的输入数据预处理方法。 取值范围:
默认配置: 参数说明:
输入节点时多于一个时,设置的节点顺序需要与 配置该参数的影响请参考: 转换内部过程解读 部分的介绍。 |
可选 |
10 |
|
参数作用:指定预处理方法的图像减去的均值。 取值范围:无。 默认配置:无。 参数说明:当 或 对于每一个输入节点而言,存在两种配置方式。 第一种是仅配置一个数值,表示所有通道都减去这个均值; 第二种是提供与通道数量一致的数值(这些数值以空格分隔开), 表示每个通道都会减去不同的均值。 配置的输入节点数量必须与 如果存在某个节点不需要 多个值的配置方法请参考 param_value配置。 |
可选 |
11 |
|
参数作用:指定预处理方法的数值scale系数。 取值范围:无。 默认配置:无。 参数说明:当
对于每一个输入节点而言,存在两种配置方式。 第一种是仅配置一个数值,表示所有通道都乘以这个系数; 第二种是提供与通道数量一致的数值(这些数值以空格分隔开), 表示每个通道都会乘以不同的系数。 配置的输入节点数量必须与 如果存在某个节点不需要 多个值的配置方法请参考 param_value配置。 |
可选 |
🛠️ 校准参数组
编 号 |
参数名称 |
参数配置说明 |
可选/ 必选 |
|---|---|---|---|
1 |
|
参数作用:指定模型校准使用的标定样本的存放目录。 取值范围:无。 默认配置:无。 参数说明:目录内校准数据需要符合输入配置的要求。 具体请参考 校准数据准备
部分的介绍。配置多个输入节点时,
设置的节点顺序需要与 多个值的配置方法请参考 param_value配置。 当calibration_type为 注意:
为了方便您的使用,如果未发现cal_data_type的配置,我们将根据文件夹
后缀对数据类型进行配置。如果文件夹后缀以 |
可选 |
2 |
|
参数作用:指定校准数据二进制文件的数据存储类型。 取值范围: 默认配置:无。 参数说明:指定模型校准时使用的二进制文件的数据存储类型。 没有指定值的情况下将会使用文件夹名字后缀来做判断。 多个值的配置方法请参考 param_value配置。 |
可选 |
3 |
|
参数作用:开启图片校准样本自动处理。 取值范围: 默认配置: 参数说明:该选项仅适用于4维图像输入的模型, 非4维模型不要打开该选项。 在启动该功能时, 为了保证校准的效果,建议您保持该参数关闭。 使用的影响请参考 校准数据准备 部分的介绍。 |
可选 |
4 |
|
参数作用:校准使用的算法类型。 取值范围: 默认配置: 参数说明: 使用
如果您使用的是QAT导出的模型,则应选择 建议您先尝试 若您只想尝试对模型性能进行验证,但对精度没有要求,
则可以尝试 注意: 使用skip方式时,因其使用max+内部生成的随机校准数据进行校准, 得到的模型不可用于精度验证。 |
可选 |
5 |
|
参数作用:该参数为 用以调整 取值范围: 默认配置: 参数说明:此参数仅在 常用配置选项有:0.99999/0.99995/0.99990/0.99950/0.99900。 建议您先尝试 |
可选 |
6 |
|
参数作用:控制是否针对featuremap的每个channel进行校准。 取值范围: 默认配置: 参数说明: 建议您先尝试 |
可选 |
7 |
|
参数作用:强制指定算子在CPU上运行。 取值范围:无。 默认配置:无。 参数说明:CPU上虽然性能不及BPU,但是提供的是float精度计算。 如果您确定某些算子需要在CPU上计算, 可以通过该参数指定。 设置值为模型中的具体节点名称。 多个值的配置方法请参考 param_value配置。 |
可选 |
8 |
|
参数作用:强制指定OP在BPU上运行。 取值范围:无。 默认配置:无。 参数说明:为了保证最终量化模型的精度,少部分情况下, 转换工具会将一些具备BPU计算条件的算子放在CPU上运行。 如果您对性能有较高的要求,愿意以更多一些量化损失为代价, 则可以通过该参数明确指定算子运行在BPU上。 设置值为模型中的具体节点名称。 多个值的配置方法请参考 param_value配置。 |
可选 |
9 |
|
参数作用:使模型以int8格式输出。 取值范围: 默认配置:无。 参数说明: 指定值为set_model_output_int8时,设置模型为int8格式低精度输出。 |
可选 |
🛠️ 编译参数组
编 号 |
参数名称 |
参数配置说明 |
可选/ 必选 |
|---|---|---|---|
1 |
|
参数作用:编译策略选择。 取值范围: 默认配置: 参数说明:
如果模型没有严重超过预期的带宽占用,建议您使用 |
可选 |
2 |
|
参数作用:是否打开编译的debug信息。 取值范围: 默认配置: 参数说明:开启该参数情况下, 编译后模型将附带一些调试信息, 用于支持后续的调优分析过程。 默认情况下,建议您保持该参数关闭。 |
可选 |
3 |
|
参数作用:模型运行核心数。 取值范围: 默认配置: 参数说明:地平线平台支持利用多个加速器核心同时完成一个推理任务, 多核心适用于输入尺寸较大的情况, 理想状态下的双核速度可以达到单核的1.5倍左右。 如果您的模型输入尺寸较大,对于模型速度有极致追求,
可以配置 |
可选 |
4 |
|
参数作用:模型编译的优化等级选择。 取值范围: 默认配置: 参数说明:优化等级可选范围为
正常用于生产和验证性能的模型,
必须使用 某些流程验证或精度调试过程中, 可以尝试使用更低级别优化加快过程速度。 |
可选 |
5 |
|
参数作用:设置上板bin模型的输入数据来源。 取值范围: 默认配置: 无,默认会根据input_type_rt的值从可选范围中自动选择。 参数说明:这个参数是适配工程环境的选项, 建议您已经全部完成模型检查后再配置。
具体在工程环境中如何适配 此参数配置有些特殊,例如模型输入名称为 data,
数据源为内存(ddr), 则此处应该配置值为 |
可选 |
6 |
|
参数作用:指定模型的每个function call的最大可连续执行时间(单位μs)。 取值范围: 默认配置: 参数说明:编译后的数据指令模型在BPU上进行推理计算时, 它将表现为1个或者多个function-call(BPU的执行粒度)的调用。 取值为0代表不做限制。 该参数用来限制每个function-call最大的执行时间, 模型只有在单个function-call执行完时才有机会被抢占。 详情参见 模型优先级控制 部分的介绍。 注意:
|
可选 |
7 |
|
参数作用:设置编译bin模型时的进程数。 取值范围: 默认配置:无。 参数说明:在编译bin模型时,用于设置进程数。 一定程度上可提高编译速度。 |
可选 |
8 |
|
参数作用:用于提示模型编译后预估的耗时增加的情况,单位是微秒。 取值范围:自然数。 默认配置:无。不设置或设置为0则表示不开启。 参数说明:模型在编译过程中,工具链内部会进行耗时分析。而实际过程中, 如算子做数据对齐等操作时会导致耗时有所增加,设置该参数后, 当某个OP的实际计算耗时与预估计算耗时的偏差大于您指定的值时,会打印相关log, 包括耗时变化的信息、数据对齐前后的shape以及padding比例等信息。 |
可选 |
🛠️ 自定义算子参数组
编 号 |
参数名称 |
参数配置说明 |
可选/ 必选 |
|---|---|---|---|
1 |
|
参数作用:自定义算子策略选择。 取值范围: 默认配置:无。 参数说明:目前仅支持register策略,具体使用请参考 自定义算子开发。 |
可选 |
2 |
|
参数作用:自定义算子的Python实现文件名称。 取值范围:无。 默认配置:无。 参数说明:多个文件可用 |
可选 |
3 |
|
参数作用:自定义算子的Python实现文件存放路径。 取值范围:无。 默认配置:无。 参数说明:设置路径时,请使用相对路径。 |
可选 |
4.1.1.6.1.2. param_value配置¶
具体参数的设置形式为:param_name: 'param_value' ,参数存在多个值时使用 ';' 符号分隔:
param_name: 'param_value1; param_value2; param_value3' 。
小技巧
当模型为多输入模型时,强烈建议您将 input_shape 等参数们显式的写出,以免造成参数对应顺序上的错误。
注意
请注意,如果设置
input_type_rt为nv12或yuv444,则模型的输入尺寸中不能出现奇数。请注意,目前XJ3上暂不支持
input_type_rt为yuv444且input_layout_rt为NCHW组合的场景。
4.1.1.6.2. 转换内部过程解读¶
模型转换完成浮点模型到地平线混合异构模型的转换。 为了使得这个异构模型能快速高效地在嵌入式端运行, 模型转换重点在解决 输入数据处理 和 模型优化编译 两个问题,本节会依次围绕这两个重点问题展开。
输入数据处理 方面地平线的边缘计算平台会为某些特定类型的输入通路提供硬件级的支撑方案,
但是这些方案的输出不一定符合模型输入的要求。
例如视频通路方面就有视频处理子系统,为采集提供图像裁剪、缩放和其他图像质量优化功能,这些子系统的输出往往是yuv420格式图像,
而我们的算法模型往往是基于bgr/rgb等一般常用图像格式训练得到的。
地平线针对此种情况提供的固定解决方案是,每个转换模型都提供两份输入信息描述,
一份用于描述原始浮点模型输入( input_type_train 和 input_layout_train),
另一份则用于描述我们需要对接的边缘平台输入数据( input_type_rt 和 input_layout_rt)。
图像数据的mean/scale也是比较常见的操作,显然yuv420等边缘平台数据格式不再适合做这样的操作, 因此,我们也将这些常见图像前处理固化到了模型中。 经过以上两种处理后,转换产出的异构模型的输入部分将变成如下图状态。

上图中的数据排布就只有NCHW和NHWC两种数据排布格式,N代表数量、C代表channel、H代表高度、W代表宽度,
两种不同的排布体现的是不同的内存访问特性。在TensorFlow模型NHWC较常用,Caffe中就都使用NCHW,
地平线平台不会限制使用的数据排布,但是有两条要求:第一是 input_layout_train 必须与原始模型的数据排布一致;
第二是在边缘平台准备好与 input_layout_rt 一致排布的数据,正确的数据排布指定是顺利解析数据的基础。
工具会根据 input_type_rt 和 input_type_train 指定的数据格式自动添加数据转换节点,根据地平线的实际生产经验,
并不是任意type组合都是需要的,为了避免您误用,我们只开放了一些固定的type组合如下表。
|
nv12 |
yuv444 |
rgb |
bgr |
gray |
featuremap |
yuv444 |
Y |
Y |
N |
N |
N |
N |
rgb |
Y |
Y |
Y |
Y |
N |
N |
bgr |
Y |
Y |
Y |
Y |
N |
N |
gray |
N |
N |
N |
N |
Y |
N |
featuremap |
N |
N |
N |
N |
N |
Y |
注解
表格中第一行是 input_type_rt 中支持的类型,第一列是 input_type_train 支持的类型,
其中的 Y/N 表示是否支持相应的 input_type_rt 到 input_type_train 的转换。
在转换得到的最终产出bin模型中, input_type_rt 到 input_type_train 是一个内部的过程,
您只需要关注 input_type_rt 的数据格式即可。
正确理解每种 input_type_rt 的要求,对于嵌入式应用准备推理数据很重要,以下是对
input_type_rt 每种格式的说明:
rgb、bgr和gray都是比较常见的图像数据,注意每个数值都采用UINT8表示。
yuv444是一种常见的图像格式,注意每个数值都采用UINT8表示。
nv12是常见的yuv420图像数据,每个数值都采用UINT8表示。
nv12有个比较特别的情况是
input_space_and_range设置bt601_video(参考前文对input_space_and_range参数的介绍),较于常规nv12情况,它的数值范围由[0,255]变成了[16,235], 每个数值仍然采用UINT8表示。featuremap适用于以上列举格式不满足您需求的情况,此type每个数值采用float32表示。 例如雷达和语音等模型处理就常用这个格式。
小技巧
以上 input_type_rt 与 input_type_train 是固化在工具链的处理流程中,如果您非常确定不需要转换,
将两个 input_type 设置成一样就可以了,一样的 input_type 会做直通处理,不会影响模型的实际执行性能。
同样的,数据前处理也是固化在流程中,如果您不需要做任何前处理,通过 norm_type 配置关闭这个功能即可,不会影响模型的实际执行性能。
模型优化编译 方面完成了模型解析、模型优化、模型校准与量化、模型编译几个重要阶段,其内部工作过程如下图所示。
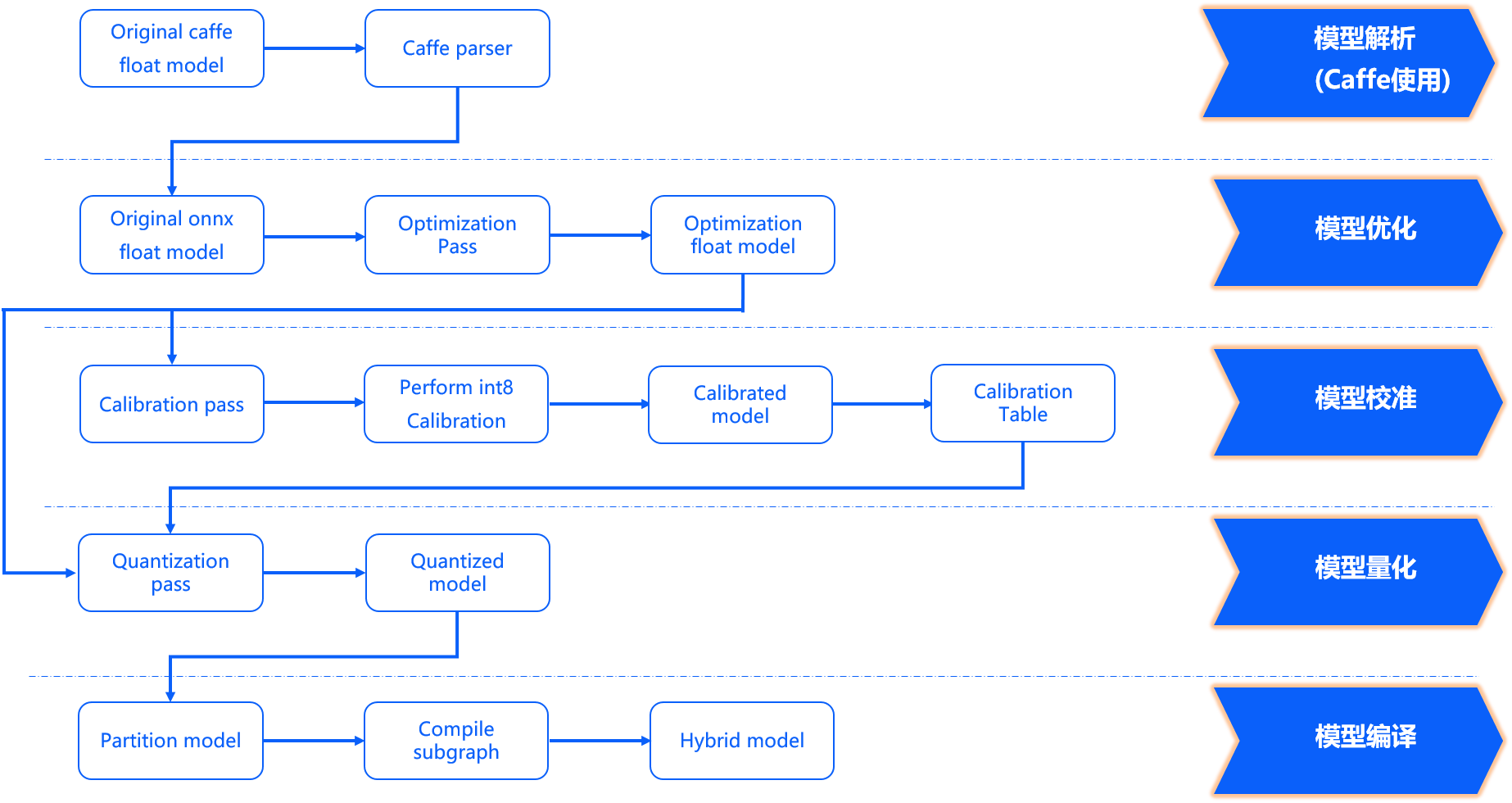
模型解析阶段 对于Caffe浮点模型会完成到ONNX浮点模型的转换。 在原始浮点模型上会根据转换配置中的配置参数决定是否加入数据预处理节点,此阶段产出一个original_float_model.onnx。 这个ONNX模型计算精度仍然是float32,在输入部分加入了一个数据预处理节点。
理想状态下,这个预处理节点应该完成 input_type_rt 到 input_type_train 的完整转换,
实际情况是整个type转换过程会配合地平线处理器硬件完成,ONNX模型里面并没有包含硬件转换的部分。
因此ONNX的真实输入类型会使用一种中间类型,这种中间类型就是硬件对 input_type_rt 的处理结果类型,
数据layout(NCHW/NHWC)会保持原始浮点模型的输入layout一致。
每种 input_type_rt 都有特定的对应中间类型,如下表:
nv12 |
yuv444 |
rgb |
bgr |
gray |
featuremap |
yuv444_128 |
yuv444_128 |
RGB_128 |
BGR_128 |
GRAY_128 |
featuremap |
注解
表格中第一行加粗部分是 input_type_rt 指定的数据类型,第二行是特定 input_type_rt 对应的中间类型,
这个中间类型就是original_float_model.onnx的输入类型。每个类型解释如下:
yuv444_128 是yuv444数据减去128结果,每个数值采用int8表示。
RGB_128 是RGB数据减去128的结果,每个数值采用int8表示。
BGR_128 是BGR数据减去128的结果,每个数值采用int8表示。
GRAY_128 是gray数据减去128的结果,每个数值采用int8表示。
featuremap 是一个四维张量数据,每个数值采用float32表示。
模型优化阶段 实现模型的一些适用于地平线平台的算子优化策略,例如BN融合到Conv等。 此阶段的产出是一个optimized_float_model.onnx,这个ONNX模型的计算精度仍然是float32,经过优化后不会影响模型的计算结果。 模型的输入数据要求还是与前面的original_float_model一致。
模型校准阶段 会使用您提供的校准数据来计算必要的量化参数,通过校准数据计算得到的每个节点对应的量化参数并将其保存在校准节点中,此阶段的产出是calibrated_model.onnx。
模型量化阶段 使用校准得到的参数完成模型量化,此阶段的产出是一个quantized_model.onnx。
这个模型的计算精度已经是int8,使用这个模型可以评估到模型量化带来的精度损失情况。
这个模型要求输入的基本数据格式和layout仍然与 original_float_model 一样,不过取值范围已经发生了变化,
整体较于 original_float_model 输入的变化情况描述如下:
数据layout均使用NHWC。
当
input_type_rt的取值为非featuremap时,则输入的数据类型均使用INT8, 反之, 当input_type_rt取值为featuremap时,则输入的数据类型则为float32。
数据排布layout关系对应如下例:
原模型输入layout:NCHW。
input_layout_train: NCHW。
origin.onnx输入layout:NCHW。
calibrated_model.onnx输入layout:NCHW。
quanti.onnx输入layout:NHWC。
即:input_layout_train、origin.onnx、calibrated_model.onnx、quanti.onnx输入的layout与原模型输入的layout一致。
注意
请注意,如果input_type_rt为nv12时,对应quanti.onnx的输入layout都是NHWC。
模型编译阶段 会使用地平线模型编译器,将量化模型转换为地平线平台支持的计算指令和数据, 这个阶段的产出一个***.bin模型,这个bin模型是后续将在地平线边缘嵌入式平台运行的模型,也就是模型转换的最终产出结果。
4.1.1.6.3. 转换结果解读¶
本节将依次介绍模型转换成功状态的解读、转换不成功的分析方式。
确认模型转换成功,需要您从 makertbin 状态信息、相似度信息和 working_dir 产出三个方面确认。
makertbin 状态信息方面,转换成功将在控制台输出信息尾部给出明确的提示信息如下:
2021-04-21 11:13:08,337 INFO Convert to runtime bin file successfully!
2021-04-21 11:13:08,337 INFO End Model Convert
相似度信息也存在于 makertbin 的控制台输出内容中,在 makertbin 状态信息之前,其内容形式如下:
======================================================================
Node ON Subgraph Type Cosine Similarity Threshold
----------------------------------------------------------------------
... ... ... ... 0.999936 127.000000
... ... ... ... 0.999868 2.557209
... ... ... ... 0.999268 2.133924
... ... ... ... 0.996023 3.251645
... ... ... ... 0.996656 4.495638
上面列举的输出内容中,Node、ON、Subgraph、Type与 hb_mapper checker 工具的解读是一致的,
请参考前文 检查结果解读 ;
Threshold是每个层次的校准阈值,用于异常状态下向地平线技术支持反馈信息,正常状况下不需要关注;
Cosine Similarity反映的Node指示的节点中,原始浮点模型与量化模型输出结果的余弦相似度。
注意
需要您特别注意的是,Cosine Similarity只是指明量化后数据稳定性的一种参考方式,对于模型精度的影响不存在明显的直接关联关系。 一般情况下,输出节点的相似度低于0.8就有了较明显的精度损失,当然由于与精度不存在绝对的直接关联, 完全准确的精度情况还需要您参考 模型精度分析与调优 的介绍。
转换产出存放在转换配置参数 working_dir 指定的路径中,成功完成模型转换后,
您可以在该目录下得到以下文件(***部分是您通过转换配置参数 output_model_file_prefix 指定的内容):
***_original_float_model.onnx
***_optimized_float_model.onnx
***_calibrated_model.onnx
***_quantized_model.onnx
***.bin
转换产出物解读 介绍了每个产出物的用途。 不过在上板运行前,我们强烈建议您完成 验证模型 和 模型性能分析与调优 介绍的性能&精度评测过程,避免将模型转换问题延伸到后续嵌入式端。
如果以上验证模型转换成功的三个方面中,有任一个出现缺失都说明模型转换出现了错误。
一般情况下,makertbin 工具会在出现错误时将错误信息输出至控制台,
例如我们在Caffe模型转换时不配置 prototxt 和 caffe_model 参数,工具给出如下提示。
2021-04-21 14:45:34,085 ERROR Key 'model_parameters' error:
Missing keys: 'caffe_model', 'prototxt'
2021-04-21 14:45:34,085 ERROR yaml file parse failed. Please double check your input
2021-04-21 14:45:34,085 ERROR exception in command: makertbin
如果以上步骤不能帮助您发现问题,欢迎在地平线唯一官方技术社区(https://developer.horizon.ai/)提出您的问题, 我们将在24小时内给您提供支持。
4.1.1.6.4. 转换产出物解读¶
上文提到模型成功转换的产出物包括以下部分,本节将介绍每个产出物的用途:
***_original_float_model.onnx
***_optimized_float_model.onnx
***_calibrated_model.onnx
***_quantized_model.onnx
***.bin
***_original_float_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型计算精度与转换输入的原始浮点模型是一模一样的,有个重要的变化就是为了适配地平线平台添加了一些数据预处理计算。 一般情况下,您不需要使用这个模型,在转换结果出现异常时,如果能把这个模型提供给地平线的技术支持,将有助于帮助您快速解决问题。
***_optimized_float_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型经过一些算子级别的优化操作,常见的就是算子融合。 通过与original_float模型的可视化对比,您可以明显看到一些算子结构级别的变化,不过这些都不影响模型的计算精度。 一般情况下,您不需要使用这个模型,在转换结果出现异常时,如果能把这个模型提供给地平线的技术支持,将有助于帮助您快速解决问题。
***_calibrated_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型是模型转换工具链将浮点模型经过结构优化后,通过校准数据计算得到的每个节点对应的量化参数并将其保存在校准节点中得到的中间产物。
***_quantized_model.onnx的产出过程可以参考 转换内部过程解读 的介绍, 这个模型已经完成了校准和量化过程,量化后的精度损失情况可以从这里查看。 这个模型是精度验证过程中必须要使用的模型,具体使用方式请参考 模型精度分析与调优 部分的介绍。
***.bin就是可以用于在地平线计算平台上加载运行的模型, 配合 嵌入式应用开发指导 部分介绍的内容, 您就可以将模型快速在计算平台上部署运行。不过为了确保模型的性能与精度效果是符合您的预期的, 我们强烈建议完成 模型性能分析与调优 和 模型精度分析与调优 介绍的性能和精度分析过程后再进入到应用开发和部署。