3.2. 算法模型PTQ量化+上板 快速上手¶
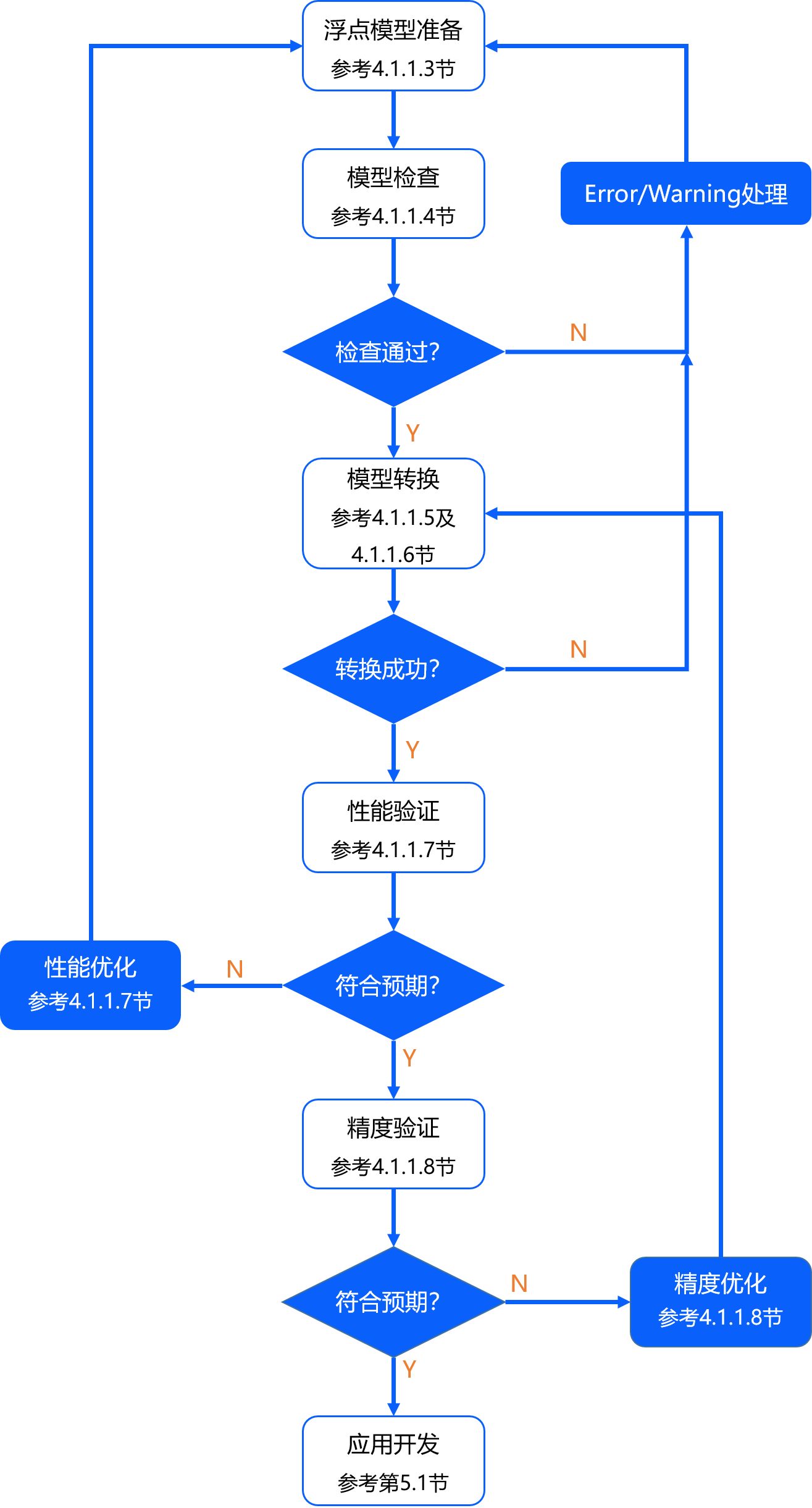
本章节中,我们将为您介绍训练后量化PTQ方案的基本使用流程,便于您实现快速上手。 这里我们以MobileNet-v1模型为例,为您进行使用演示,详细内容将在后续章节为您展开介绍,基本工作流程如下图所示。
注意
请注意,在您进行以下操作前,请确保您已经参考 环境部署 章节完成了开发机和开发板上的环境安装。
3.2.1. 浮点模型准备¶
OE包在 ddk/samples/ai_toolchain/horizon_model_convert_sample 路径下为您提供了丰富的PTQ模型示例,
其中MobileNet-v1模型示例位于 03_classificarion/01_mobilenet 路径下。
请先执行其中的 00_init.sh 脚本来获取示例对应的校准数据集和原始模型。
示例模型的模型来源和相关说明请参考 如何准备模型 章节。
如您需要转换私有模型,请参考 浮点模型准备 章节内容 提前准备好 caffe1.0 或 opset=10/11 的 onnx 模型。下表为不同框架到ONNX模型格式转换的参考方案:
训练框架 |
参考方案 |
|---|---|
Pytorch |
使用官方API导出: https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html |
Tensorflow |
使用ONNX社区的onnx/tensorflow-onnx工具转换: https://github.com/onnx/tensorflow-onnx |
PaddlePaddle |
使用官方API导出: https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/onnx/export_cn.html |
MXNet2Onnx |
使用官方API导出: https://github.com/dotnet/machinelearning/blob/main/test/Microsoft.ML.Tests/OnnxConversionTest.cs |
其他框架 |
3.2.2. 模型验证¶
在浮点模型准备好之后,我们建议先进行快速的模型验证,以确保其符合计算平台的支持约束。 对于Caffe1.0框架的MobileNet-v1模型,我们可以在命令行中键入以下命令完成模型验证:
hb_mapper checker --model-type caffe \
--prototxt mobilenet_deploy.prototxt \
--model mobilenet.caffemodel \
--march bernoulli2
对于ONNX格式的Efficientnet_lite0模型,则键入以下命令:
hb_mapper checker --model-type onnx \
--model efficientnet_lite0_fp32.onnx \
--march bernoulli2
其中,两个模型文件都可从 ddk/samples/model_zoo/mapper/classification 路径获取。
而 hb_mapper checker 工具的主要参数如下,更多参数说明还请参考 验证模型 章节。
参数 |
说明 |
|---|---|
--model-type |
用于指定检查输入的模型类型,目前只支持设置 caffe 或者 onnx 。 |
--march |
用于指定需要适配的处理器类型,XJ3处理器请设置为 bernoulli2 (默认值)。 |
--proto |
此参数仅在model-type指定caffe时有效,取值为caffe模型的 prototxt 文件名称; onnx模型可以不配置该参数。 |
--model |
在model-type被指定为caffe时,取值为Caffe模型的 caffemodel 文件名称; 在model-type被指定为onnx时,取值为 ONNX模型 文件名称。 |
以MobileNet-v1模型为例,您可以使用 01_check.sh 脚本快速完成模型验证。
01_check.sh 脚本文件中的主要内容如下所示:
set -ex
cd $(dirname $0) || exit
model_type="caffe"
proto="../../../01_common/model_zoo/mapper/classification/mobilenet/mobilenet_deploy.prototxt"
caffe_model="../../../01_common/model_zoo/mapper/classification/mobilenet/mobilenet.caffemodel"
march="bernoulli2"
hb_mapper checker --model-type ${model_type} \
--proto ${proto} --model ${caffe_model} \
--march ${march}
如果模型验证不通过,请根据终端打印或在当前路径下生成的 hb_mapper_checker.log 日志文件确认报错信息和修改建议,
更多说明请参考 验证模型 章节。
3.2.3. 模型转换¶
模型验证通过后,就可以使用 hb_mapper makertbin 工具进行模型转换,参考命令如下:
hb_mapper makertbin --config mobilenet_config.yaml \
--model-type caffe
其中, mobilenet_config.yaml 为模型转换对应的配置文件,将在 Yaml配置文件 中进行介绍。 model-type 则用于指定检查输入的模型类型,
可配置为caffe或者onnx,不同模型类型对应的配置文件参数会稍有不同。
另外,PTQ 方案的模型量化还需要依赖一定数量预处理后的样本进行校准,将在 校准数据预处理 中进行介绍。
3.2.3.1. Yaml配置文件¶
Yaml配置文件共包含4个必选参数组( model_parameters 、 input_parameters 、 calibration_parameters 、 compiler_parameters )和
1个可选参数组( custom_op ),每个参数组下也区分必选和可选参数(可选参数默认隐藏),具体要求和填写方式可以参考模型示例
及 模型量化与编译 章节。以下为MobileNet-v1模型的配置文件:
# 模型转化相关的参数
model_parameters:
# Caffe浮点网络数据模型文件
caffe_model: 'mobilenet.caffemodel'
# Caffe网络描述文件
prototxt: 'mobilenet_deploy.prototxt'
# 适用BPU架构
march: "bernoulli2"
# 指定模型转换过程中是否输出各层的中间结果,如果为True,则输出所有层的中间输出结果
layer_out_dump: False
# 模型转换输出的结果的存放目录
working_dir: 'model_output'
# 模型转换输出的用于上板执行的模型文件的名称前缀
output_model_file_prefix: 'mobilenetv1_224x224_nv12'
# 模型输入相关参数, 若输入多个节点, 则应使用';'进行分隔, 使用默认缺省设置则写None
input_parameters:
# (选填) 模型输入的节点名称, 此名称应与模型文件中的名称一致, 否则会报错, 不填则会使用模型文件中的节点名称
input_name: ""
# 网络实际执行时,输入给网络的数据格式,包括 nv12/rgb/bgr/yuv444/gray/featuremap
input_type_rt: 'nv12'
# 网络训练时输入的数据格式,可选的值为rgb/bgr/gray/featuremap/yuv444
input_type_train: 'bgr'
# 网络训练时输入的数据排布, 可选值为 NHWC/NCHW
input_layout_train: 'NCHW'
# (选填) 模型网络的输入大小, 以'x'分隔, 不填则会使用模型文件中的网络输入大小,否则会覆盖模型文件中输入大小
input_shape: ''
# 网络实际执行时,输入给网络的batch_size, 默认值为1
#input_batch: 1
# 网络输入的预处理方法,主要有以下几种:
# no_preprocess 不做任何操作
# data_mean 减去通道均值mean_value
# data_scale 对图像像素乘以data_scale系数
# data_mean_and_scale 减去通道均值后再乘以scale系数
norm_type: 'data_mean_and_scale'
# 图像减去的均值, 如果是通道均值,value之间必须用空格分隔
mean_value: 103.94 116.78 123.68
# 图像预处理缩放比例,如果是通道缩放比例,value之间必须用空格分隔
scale_value: 0.017
# 模型量化相关参数
calibration_parameters:
# 模型量化的参考图像的存放目录,图片格式支持Jpeg、Bmp等格式,输入的图片
# 应该是使用的典型场景,一般是从测试集中选择20~100张图片,另外输入
# 的图片要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 若有多个输入节点, 则应使用';'进行分隔
cal_data_dir: './calibration_data_bgr'
# 校准数据二进制文件的数据存储类型,可选值为:float32, uint8. 若有多个输入节点, 则应使用';'进行分隔
cal_data_type: 'float32'
# 模型量化的算法类型,支持default、mix、kl、max、load,通常采用default即可满足要求
# 如不符合预期可先尝试修改为mix 仍不符合预期再尝试kl或max
# 当使用QAT导出模型时,此参数则应设置为load
# 相关参数的技术原理及说明请您参考用户手册中的PTQ原理及步骤中参数组详细介绍部分
calibration_type: 'max'
# 该参数为'max'校准方法的参数,用以调整'max'校准的截取点。此参数仅在calibration_type为'max'时有效。
# 该参数取值范围:0.0 ~ 1.0。常用配置选项有:0.99999/0.99995/0.99990/0.99950/0.99900。
max_percentile: 0.9999
# 编译器相关参数
compiler_parameters:
# 编译策略,支持bandwidth和latency两种优化模式;
# bandwidth以优化ddr的访问带宽为目标;
# latency以优化推理时间为目标
compile_mode: 'latency'
# 设置debug为True将打开编译器的debug模式,能够输出性能仿真的相关信息,如帧率、DDR带宽占用等
debug: False
# 优化等级可选范围为O0~O3
# O0不做任何优化, 编译速度最快,优化程度最低,
# O1-O3随着优化等级提高,预期编译后的模型的执行速度会更快,但是所需编译时间也会变长。
# 推荐用O2做最快验证
optimize_level: 'O3'
其中,ONNX模型无需配置 model_parameters 参数组中的 caffe_model 和 prototxt 参数,而是替换为配置 onnx_model 参数。
input_parameters 参数组中的 input_type_rt 和 input_type_train 参数分别用于指定模型在板端实际部署时会接收到的数据类型
(如 nv12)和本身训练时的数据类型(如 rgb)。当两种数据类型不一致时,转换工具会自动在模型前端插入一个能 BPU 加速的预处理节点,以完成对应的颜色空间转换。
同时,该参数组中的 norm_type 、 mean_value 、 scale_value 参数还能用于配置图片输入模型的数据归一化操作,
配置后转换工具也会将其集成进预处理节点实现BPU加速。数据归一化的计算公式为:
\(data\_norm = (data - mean\_value) * scale\_value\)
calibration_parameters 参数组中的 cal_data_dir 参数需要配置预处理好的校准数据文件夹路径,
预处理方式的说明请参考 校准数据预处理 。
3.2.3.2. 校准数据预处理¶
注意
请注意,在进行此步之前,请确保您已经通过执行对应示例目录下的
00_init.sh脚本完成了校准数据集的获取。如果当前只关注模型性能,那么可以将yaml文件中的
calibration_type参数直接配置为skip,并跳过本小节, 工具会在模型转换时自动忽略cal_data_dir参数。
PTQ方案的校准数据一般是从训练集或验证集中筛选100份左右(可适当增减)的典型数据,并应避免非常少见的异常样本,
如纯色图片、不含任何检测或分类目标的图片等。筛选出的校准数据还需进行与模型inference前一致的预处理操作,
处理后保持与原始模型一样的数据类型( input_type_train )、layout ( input_layout_train )和尺寸( input_shape )。
对于校准数据的预处理,地平线建议直接参考示例代码进行修改使用。以MobileNet-v1模型为例,preprocess.py文件中 的calibration_transformers函数的包含了其校准数据的前处理 transformers,处理完的校准数据与其 yaml 配置文件保持一致,即:
input_type_train : ‘bgr’
input_layout_train :’NCHW’
def calibration_transformers():
transformers = [
ShortSideResizeTransformer(short_size=256),
CenterCropTransformer(crop_size=224),
HWC2CHWTransformer(),
RGB2BGRTransformer(data_format="CHW"),
ScaleTransformer(scale_value=255),
]
return transformers
其中,transformers都定义在 ../../../01_common/python/data/transformer.py 文件中,具体说明
请参考 图片处理transformer说明 ,您可以按需选用或者自定义修改及扩展。
注意
需要注意的是,如果已经在yaml文件中配置了数据归一化来启用BPU加速,那么应避免在此处的transformers中重复操作。
修改完preprocess.py文件后,即可修改02_preprocess.sh脚本并执行,以完成校准数据的预处理。
bash 02_preprocess.sh
02_preprocess.sh脚本文件的主要内容如下:
set -e -v
cd $(dirname $0) || exit
python3 ../../../data_preprocess.py \
--src_dir ../../../01_common/calibration_data/imagenet \
--dst_dir ./calibration_data_bgr \
--pic_ext .bgr \
--read_mode skimage \
--saved_data_type float32
data_preprocess.py文件的传参说明如下:
src_dir为原始校准数据路径。
dst_dir为处理后数据的存放路径,可自定义。
pic_ext为处理后数据的文件后缀,主要用于帮助记忆数据类型,可不配置。
read_mode为图片读取方式,可配置为skimage或opencv。需要注意的是,skimage读取的图片类型为RGB, 数据范围为0-1,而opencv读取的图片类型为BGR,数据范围为0-255。
saved_data_type为处理后数据的保存类型。
如果您选择自行编写python代码实现校准数据预处理,那么可以使用 numpy.tofile 命令将其保存为float32
格式的二进制文件, 工具链校准时会基于 numpy.fromfile 命令进行读取。
3.2.3.3. 转换模型¶
准备完校准数据和yaml配置文件后,即可一步命令完成模型解析、图优化、校准、量化、编译的全流程转换, 内部过程详解请参考 转换内部过程解读 章节。 以MobileNet-v1模型为例的模型转换参考命令如下:
hb_mapper makertbin --config mobilenet_config.yaml \
--model-type caffe
转换完成后,会在yaml文件配置的 working_dir 路径下保存各阶段流程产出的模型文件和编译器预估的
模型BPU部分的静态性能评估文件,详细说明请参考 转换产出物解读 章节。
|-- MOBILENET_subgraph_0.html # 静态性能评估文件(可读性更好)
|-- MOBILENET_subgraph_0.json # 静态性能评估文件
|-- mobilenetv1_224x224_nv12.bin # 用于在地平线计算平台上加载运行的模型
|-- mobilenetv1_224x224_nv12_optimized_float_model.onnx
|-- mobilenetv1_224x224_nv12_original_float_model.onnx
|-- mobilenetv1_224x224_nv12_calibrated_model.onnx
`-- mobilenetv1_224x224_nv12_quantized_model.onnx
3.2.4. 性能快速验证¶
针对转换生成的 xxx.bin 模型文件,地平线既支持先在开发机端预估模型BPU部分的的静态性能,
也在板端提供给了无需任何代码开发的可执行工具快速评测动态性能,以下将分别进行介绍。
更详细的说明和性能调优建议请参考 模型性能分析与调优 章节。
3.2.4.1. 静态性能评估¶
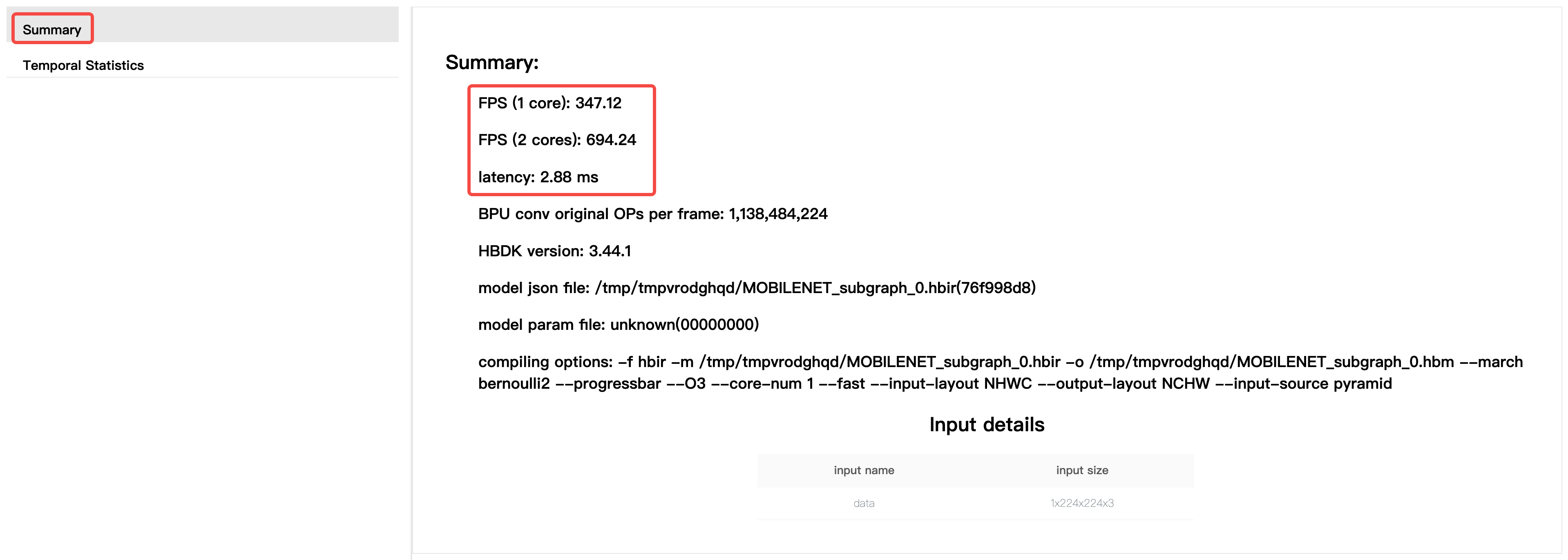
如 转换模型 所述,模型成功转换后会在 working_dir 路径下生成包含模型静态性能预估的html和json文件,两者内容相同,
但html文件的可读性更好。以下为MobileNet-v1模型转换生成的html文件,其中:
Summary选项卡提供了编译器预估的模型BPU部分性能(不包含CPU算子性能预估)。
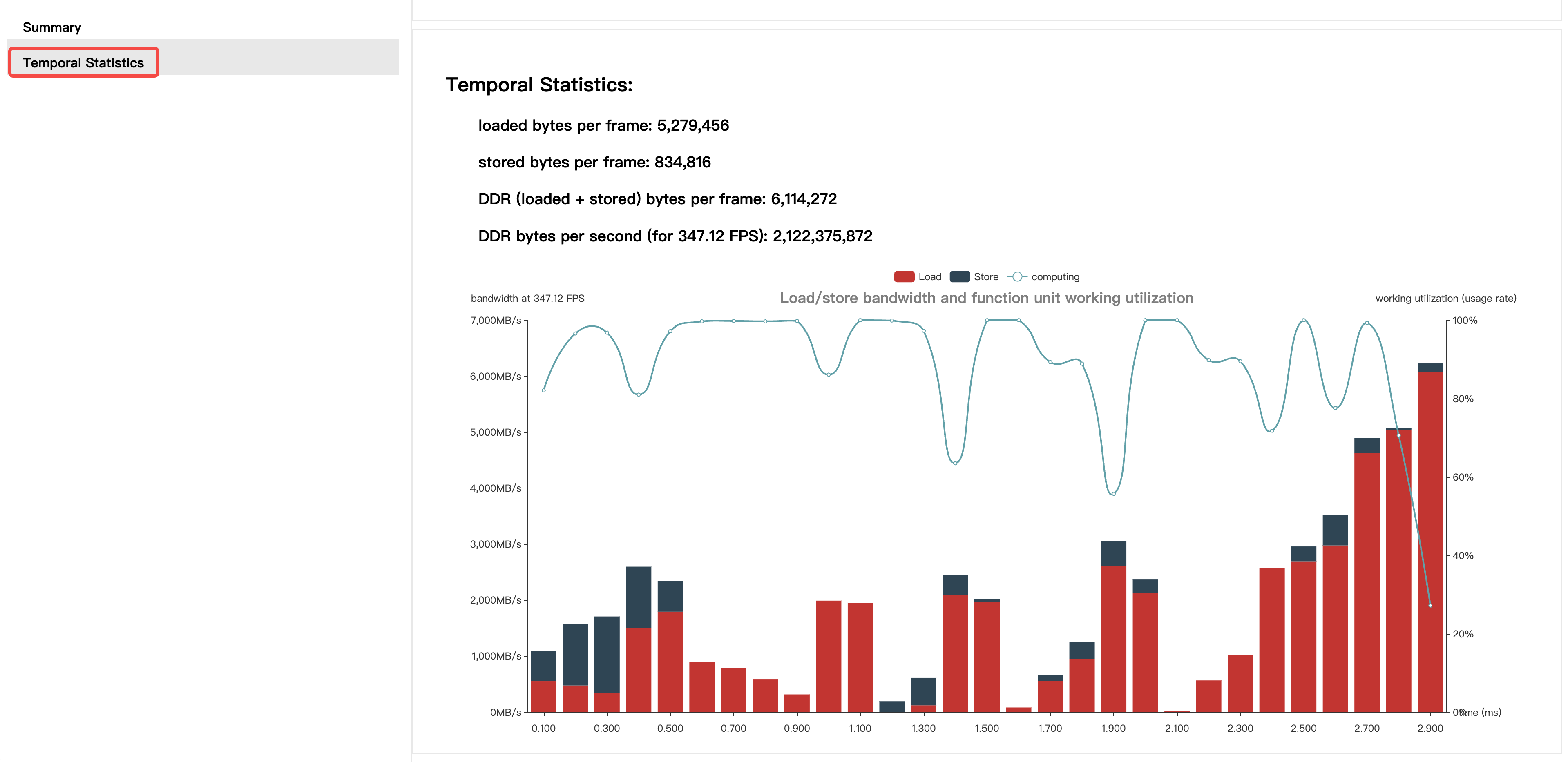
Temporal Statistics选项卡内则主要提供了模型一帧推理时间内的带宽占用情况。
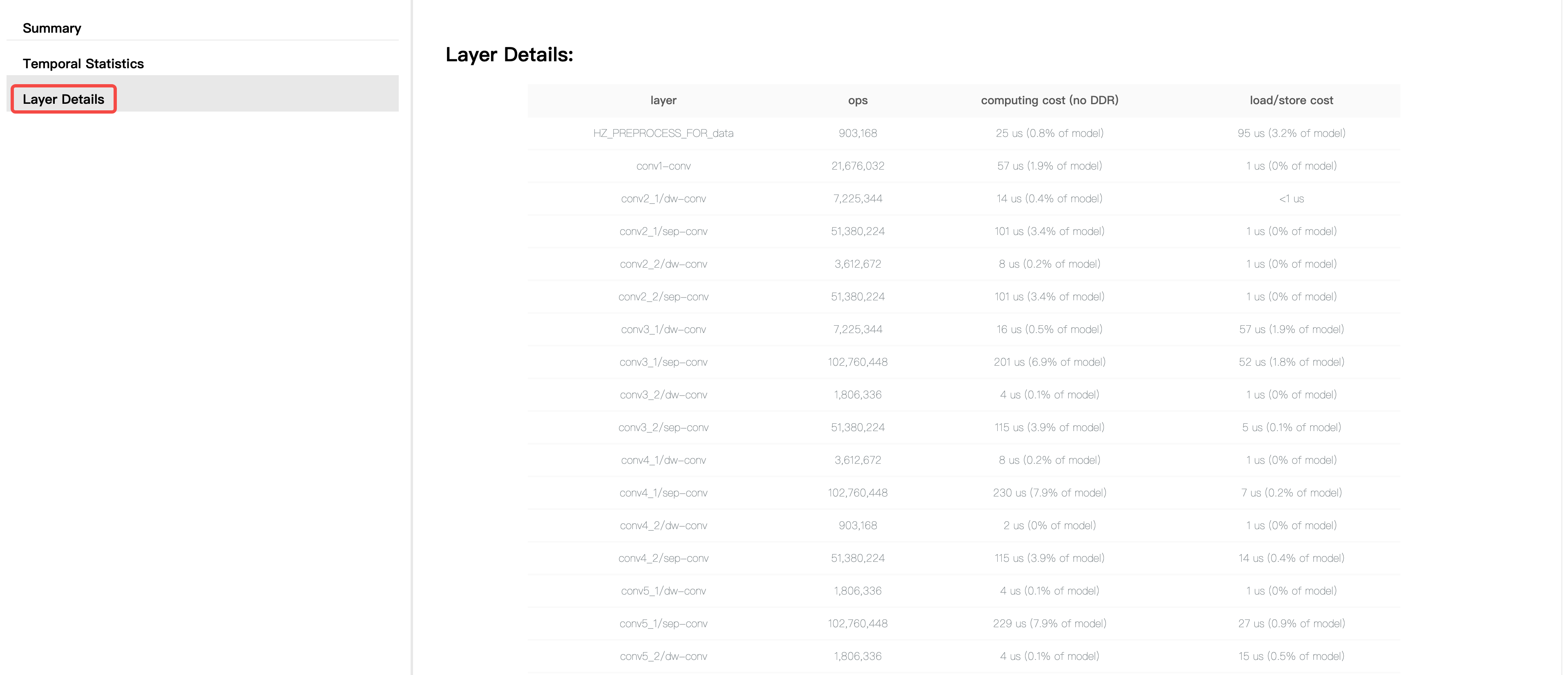
另外,如果我们在yaml文件
compiler_parameters参数组内配置了debug参数为True,那么html文件中 还会增加Layer Details选项卡,其中包含了每一层BPU算子的计算量、计算耗时和数据搬运耗时。
针对 xxx.bin 模型,地平线在开发机环境还提供了 hb_perf 工具 重新生成静态性能预估文件。其使用方式如下,
详细说明请参考 使用hb_perf工具估计性能 章节。
hb_perf xxx.bin
当模型的静态性能已经不符合预期时,请参考 模型性能优化 章节进行性能调优。
3.2.4.2. 动态性能评估¶
当模型的静态性能符合预期后,我们可以进一步上板实测模型的动态性能,其参考方式如下:
1.首先请确保已按照 环境部署 章节完成开发板环境部署。
2.将转换生成的 xxx.bin 模型拷贝至开发板 /userdata 文件夹下任意路径。
3.通过 hrt_model_exec perf 工具快捷评估模型的耗时和帧率。
# 将模型拷贝至开发板
scp model_output/mobilenetv1_224x224_nv12.bin root@{board_ip}:/userdata
# 登录开发板评测性能
ssh root@{board_ip}
cd /userdata
# 单BPU核单线程串行状态下评测latency
hrt_model_exec perf --model_file mobilenetv1_224x224_nv12.bin --thread_num 1 --frame_count 1000
# 双BPU核多线程并发状态下评测FPS
hrt_model_exec perf --model_file mobilenetv1_224x224_nv12.bin --core_id 0 --thread_num 8 --frame_count 1000
hrt_model_exec 工具的主要参数说明如下,更多说明请参考 hrt_model_exec工具介绍 章节。
参数 |
类型 |
说明 |
|---|---|---|
model_file |
string |
[必选]模型文件路径 |
core_id |
int |
[可选]用于指定BPU运行核心,默认值为0。 0:任意核,预测库会根据负载情况自动分配调度。 1:core0。 2:core1。 |
thread_num |
int |
[可选]程序运行线程数,可选范围[1,8],默认值1。 |
frame_count |
int |
[可选]模型运行总帧数,默认值200。 |
profile_path |
string |
[可选]统计工具日志产生路径,运行产生profiler.log和profiler.csv,分析op耗时和调度耗时。 |
注解
如果您在板端无法找到
hrt_model_exec工具,可以再执行一次OE包中ddk/package/board路径下的install.sh脚本。评测Latency时一般采用单线程串行的推理方式,可以指定
thread_num为 1。评测FPS时一般采用多线程并发的推理方式来占满BPU资源,此时可以配置
core_id为 0,并配置thread_num为多线程。如果您配置了
profile_path参数,程序需要正常运行结束才会生成profiler.log和profiler.csv日志文件,请勿使用Ctrl+C命令中断程序。
当模型的动态性能不符合预期时,请参考 模型性能优化 章节进行性能调优。
3.2.5. 精度验证¶
当模型的性能验证符合预期后,即可进行后续的精度验证。请首先确保您已经准备好相关的评测数据集,并挂载在Docker容器中。 示例模型使用的数据集可以从以下链接获取:
数据集 |
下载地址 |
下载结构 |
|---|---|---|
ImageNet |
下载结构请您参考 ImageNet数据集参考结构 |
|
COCO |
下载结构请您参考 COCO数据集参考结构 |
|
VOC |
需要下载2007和2012两个版本,下载结构请您参考 VOC数据集参考结构 |
|
Cityscapes |
下载结构请您参考 Cityscapes数据集参考结构 |
|
CIFAR-10 |
下载结构请您参考 CIFAR-10数据集参考结构 |
如果您在数据准备过程中有遇到问题,可以前往 地平线开发者社区 发帖进行求助。
如 转换模型 所述,模型转换会生成 xxx_quantized_model.onnx 和 xxx.bin 两个量化模型,两者输出是保持数值一致的。
您也可以在开发机环境使用 hb_verifier 工具进行一致性验证,参考命令如下,
详细说明请参考 hb_verifier 工具 章节。
hb_verifier -m quanti.onnx,model.bin -b *.*.*.* -s True (-i 选填)
hb_verifier 工具的参数说明如下:
参数 |
说明 |
|---|---|
--model, -m |
[必选]定点模型名称和bin模型名称,多模型之间用”,”进行区分。 |
--board-ip/-b |
[可选]上板测试使用的arm board ip地址。 |
--run-sim/-s |
[可选]设置是否使用X86环境的libdnn做bin模型推理,默认为False。 |
--input-img/-i |
[可选]指定推理测试时使用的图片。若不指定则会使用随机生成的tensor数据。
若指定图片为二进制形式的图片文件,其文件形式需要为后缀名为 多输入模型添加图片的方式有以下两种传参方式,多张图片之间用”,”分割:
|
--compare_digits/-c |
[可选]设置比较推理结果的数值精确度(即比较数值小数点后的位数), 若不进行指定则工具会默认比较至小数点后五位。 |
--dump-all-nodes-results/-r |
[可选]设置是否保存模型中各个算子的输出结果,并对算子输出名称相同的结果进行对比,默认为False。
请您注意,目前基于性能考虑,暂不支持您在X86环境下使用dump功能。 |
相比于 xxx.bin ,地平线更建议优先在开发机Python环境评测 xxx_quantized_model.onnx 模型的量化精度,其评测方式更加简单快捷,
具体请见 开发机Python环境验证 。 xxx.bin 在板端基于C++代码的评测说明请见 开发板C++环境验证 ,
更详细的精度验证和优化建议请参考 模型精度分析与调优 章节。
3.2.5.1. 开发机Python环境验证¶
以 MobileNet-v1 模型为例,mobilenetv1_224x224_nv12_quantized_model.onnx量化模型的单张推理和验证集精度评测示例请参考
示例目录中的 04_inference.sh 和 05_evaluate.sh 脚本,参考命令如下:
# 测试量化模型单张图片推理结果
bash 04_inference.sh
# 测试浮点模型单张图片推理结果(可选)
bash 04_inference.sh origin
# 测试量化模型精度,请确保您的评测数据集已正确挂载在Docker容器中
bash 05_evaluate.sh
# 测试浮点模型精度(可选)
bash 05_evaluate.sh origin
两个脚本会分别调用 ../../cls_inference.py 和 ../../cls_evaluate.py 文件进行推理,
以 cls_inference.py 文件为例,代码中的主要接口使用逻辑如下:
from horizon_tc_ui import HB_ONNXRuntime
from preprocess import infer_image_preprocess
from postprocess import postprocess
def inference(sess, image_name, input_layout, input_offset):
if input_layout is None:
input_layout = sess.layout[0]
# 前处理
image_data = infer_image_preprocess(image_name, input_layout)
input_name = sess.input_names[0]
output_name = sess.output_names
# 模型推理
output = sess.run(output_name, {input_name: image_data},
input_offset=input_offset)
# 后处理
top_five_label_probs = postprocess(output)
def main(model, image, input_layout, input_offset):
sess = HB_ONNXRuntime(model_file=model)
sess.set_dim_param(0, 0, '?')
inference(sess, image, input_layout, input_offset)
if __name__ == '__main__':
main()
其中,infer_image_preprocess函数的前处理操作来源于 校准数据预处理 章节
所述preprocess.py文件,相比于calibration_transformers函数会额外增加 input_type_train 到 input_type_rt
(参数说明请见 Yaml配置文件 章节)颜色空间的转换来对齐模型实际部署时的输入数据类型,具体代码如下:
def infer_transformers(input_layout="NHWC"):
transformers = [
ShortSideResizeTransformer(short_size=256),
CenterCropTransformer(crop_size=224),
RGB2BGRTransformer(data_format="HWC"),
ScaleTransformer(scale_value=255),
BGR2NV12Transformer(data_format="HWC"),
NV12ToYUV444Transformer((224, 224),
yuv444_output_layout=input_layout[1:]),
]
return transformers
def infer_image_preprocess(image_file, input_layout):
transformers = infer_transformers(input_layout)
image = SingleImageDataLoader(transformers,
image_file,
imread_mode='skimage')
return image
需要注意的是, xxx.bin 模型对于 input_type_train 到 input_type_rt 颜色空间的转换会配合处理器硬件完成。
而模型转换生成的几个ONNX模型前端插入的预处理节点不包含硬件转换逻辑,所以其实际输入只是一种中间类型,对应硬件
对 input_type_rt 类型的处理结果。下表为每种 input_type_rt 数据类型对应的中间类型。
以MobileNet-v1模型为例,其 input_type_rt 配置为nv12,此处transformers中就会从BGR处理成NV12,
再处理成YUV444,-128(对应uint8转int8)的操作则会在sess.run推理接口中由 input_offset 参数传入。
input_type_rt |
nv12 |
yuv444 |
rgb |
bgr |
gray |
featuremap |
|---|---|---|---|---|---|---|
中间类型 |
yuv444_128 |
yuv444_128 |
RGB_128 |
BGR_128 |
GRAY_128 |
featuremap |
注解
_128表示数据会减去128,由uint8类型转换为int8类型。
3.2.5.2. 开发板C++环境验证¶
在开发板端,地平线也提供了一套适配所有硬件平台的嵌入式端预测库LibDNN,来帮助用户快速完成模型的部署工作, 并提供了相关示例。您可以首先参考 模型部署 章节学习模型部署和BPU SDK API接口的基础使用, 再参考 AI-Benchmark 章节学习示例模型精度评测的完整代码框架。
3.2.5.2.1. 模型部署¶
OE包提供了模型部署的基础示例,以便于用户学习LibDNN预测库API接口的使用方式, 示例的详细说明可以参考 基础示例包使用说明 章节。
注意
请注意,在您进行模型部署前,需要先获取上板使用的模型:
在
ddk/samples/ai_toolchain/model_zoo/runtime/ai_benchmark目录下, 执行resolve_ai_benchmark_ptq.sh。在
ddk/samples/ai_toolchain/model_zoo/runtime/horizon_runtime_sample目录下, 执行resolve_runtime_sample.sh。
其中,示例目录下的 code/00_quick_start/src/run_mobileNetV1_224x224.cc 文件提供了MobileNet-v1模型
从DDR读取数据,到模型推理,再执行后处理出分类结果的完整流程代码。从摄像头输入的全链路示例可以
参考 ddk/samples/ai_forward_view_sample 。
run_mobileNetV1_224x224.cc中的主要代码逻辑包括以下6个步骤,代码中所涉及的API接口的具体说明 可以参考 BPU SDK API手册 章节。
1.加载模型,获取模型句柄。
2.准备模型输入输出tensor,申请对应的BPU内存空间。
3.读取模型输入数据,并放入申请好的输入tensor中。
4.推理模型,获取模型输出。
5.基于输出tensor中的数据实现模型后处理。
6.释放相关资源。
int main(int argc, char **argv) {
// Step1: get model handle
{
hbDNNInitializeFromFiles(&packed_dnn_handle, &modelFileName, 1);
hbDNNGetModelNameList(&model_name_list, &model_count, packed_dnn_handle);
hbDNNGetModelHandle(&dnn_handle, packed_dnn_handle, model_name_list[0]);
}
// Step2: prepare input and output tensor
std::vector<hbDNNTensor> input_tensors;
std::vector<hbDNNTensor> output_tensors;
int input_count = 0;
int output_count = 0;
{
hbDNNGetInputCount(&input_count, dnn_handle);
hbDNNGetOutputCount(&output_count, dnn_handle);
input_tensors.resize(input_count);
output_tensors.resize(output_count);
prepare_tensor(input_tensors.data(), output_tensors.data(), dnn_handle);
}
// Step3: set input data to input tensor
{
// read a single picture for input_tensor[0], for multi_input model, you
// should set other input data according to model input properties.
read_image_2_tensor_as_nv12(FLAGS_image_file, input_tensors.data());
}
// Step4: run inference
{
// make sure memory data is flushed to DDR before inference
for (int i = 0; i < input_count; i++) {
hbSysFlushMem(&input_tensors[i].sysMem[0], HB_SYS_MEM_CACHE_CLEAN);
}
hbDNNInferCtrlParam infer_ctrl_param;
HB_DNN_INITIALIZE_INFER_CTRL_PARAM(&infer_ctrl_param);
hbDNNInfer(&task_handle,
&output,
input_tensors.data(),
dnn_handle,
&infer_ctrl_param);
// wait task done
hbDNNWaitTaskDone(task_handle, 0);
}
// Step5: do postprocess with output data
std::vector<Classification> top_k_cls;
{
// make sure CPU read data from DDR before using output tensor data
for (int i = 0; i < output_count; i++) {
hbSysFlushMem(&output_tensors[i].sysMem[0], HB_SYS_MEM_CACHE_INVALIDATE);
}
get_topk_result(output, top_k_cls, FLAGS_top_k);
for (int i = 0; i < FLAGS_top_k; i++) {
VLOG(EXAMPLE_REPORT) << "TOP " << i << " result id: " << top_k_cls[i].id;
}
}
// Step6: release resources
{
// release task handle
hbDNNReleaseTask(task_handle);
// free input mem
for (int i = 0; i < input_count; i++) {
hbSysFreeMem(&(input_tensors[i].sysMem[0]));
}
// free output mem
for (int i = 0; i < output_count; i++) {
hbSysFreeMem(&(output_tensors[i].sysMem[0]));
}
// release model
hbDNNRelease(packed_dnn_handle);
}
return 0;
}
该示例运行的参考方式如下:
# 开发机环境执行交叉编译,生成可执行程序
cd /open_explorer/ddk/samples/ai_toolchain/horizon_runtime_sample/code
bash build_xj3.sh
# 拷贝xj3目录至板端
mkdir ..xj3/runtime
scp -r ../xj3/ root@{board_ip}:/userdata
# 拷贝模型文件至板端
scp -r ../../model_zoo/runtime/horizon_runtime_sample/mobilenetv1/ root@{board_ip}:/userdata/xj3/model/runtime
# 登录开发板环境
ssh root@{board_ip}
# 进入xj3/script/目录下,执行相应运行脚本即可
cd /userdata/xj3/script/00_quick_start/
bash run_mobilenetV1.sh
3.2.5.2.2. AI-Benchmark¶
OE包在 ddk/samples/ai_benchmark 路径下还提供了典型分类、检测、分割示例模型板端性能和精度评测的示例包,您可以基于这些示例进行进一步的应用开发。
以下 示例使用 章节将介绍示例的使用方式, 代码结构 章节将简单介绍示例的代码结构。
3.2.5.2.2.1. 示例使用¶
示例包的使用流程主要包括4个步骤,以下将依次展开介绍,更多说明请见 AI-Benchmark使用说明 章节。
步骤一:环境部署
AI-Benchmark示例使用请首先确保已按照 环境部署 章节完成开发机和开发板的环境部署。
步骤二:工程示例编译
工程示例的编译需要在开发机环境完成,参考命令如下:
# 开发机环境完成交叉编译
cd /open_explorer/ddk/samples/ai_benchmark/code
bash build_ptq_xj3.sh
编译完成后,可执行程序和对应依赖会自动拷贝至 ../xj3/ptq/script/aarch64 目录下,请将相关示例拷贝至板端,参考命令如下:
scp -r ../xj3/ptq root@{board_ip}:/userdata
步骤三:评测数据集准备
模型的精度评测需要先在开发机端完成评测数据的预处理, 如果仅执行性能评测可以跳过此步骤 。 以MobileNet-v1模型为例,ImageNet数据集的预处理命令如下:
hb_eval_preprocess -m mobilenetv1 -i imagenet/val -o ./pre_mobilenetv1
其中, hb_evel_preprocess 工具封装了地平线示例模型对应的前处理操作,工具常用参数如下,
更多说明请参考 hb_eval_preprocess 工具 章节。
参数 |
说明 |
|---|---|
-m |
[必选]模型名称,如mobilenetv1,可以通过hb_eval_preprocess -h查看可选项。 |
-i |
[必选]原始数据集路径。 |
-o |
[可选]预处理后数据集的保存路径。 |
-h, --help |
[可选]显示帮助信息。 |
预处理后生成的pre_mobilenetv1文件夹建议以以下目录结构存放:
|-- nfs
| |-- data
| | |-- imagenet
| | | |-- pre_mobilenetv1
| | | | |-- xxxx.bin # 预处理好的二进制文件
因为评测数据集一般较大,不适合直接存放在开发板上,所以更推荐采用挂载的方式(开发机端需要具备root权限) 提供给开发板读取,参考方式如下:
开发机端:
1.编辑
/etc/exports,增加一行:/nfs *(insecure,rw,sync,all_squash,anonuid=1000,anongid=1000,no_subtree_check)
其中
/nfs为本机挂载路径,可替换为用户指定目录。2.执行命令
exportfs -a -r,使/etc/exports生效。开发板端:
1.创建需要挂载的目录,例如:
mkdir -p /mnt。2.输入指令完成挂载:
mount -t nfs {PC端ip}:/nfs /mnt -o nolock。其中/nfs为本机挂载路径,/mnt为板端被挂载路径,均可替换为用户指定目录。执行成功后需要再将挂载的预处理数据目录的软连接替换至/userdata/ptq/data路径下:# 进入到开发板ptq文件夹下 cd /userdata/ptq rm -rf ./data ln -s /mnt/data ./data
最后还需要在板端执行以下命令完成lst文件的生成,lst文件包含了每一个预处理文件的路径。
find /userdata/ptq/data/imagenet/pre_mobilenetv1 -name "*bin" > /userdata/ptq/data/imagenet/pre_mobilenetv1.lst
以上准备工作完成后的板端目录结构应该如下所示:
|-- ptq | |-- data | | |-- imagenet | | | |-- pre_mobilenetv1 | | | | |-- xxxx.bin # 预处理好的二进制文件 | | | | |-- ... | | | |-- pre_mobilenetv1.lst # lst文件:记录每一个预处理文件的路径 | |-- model | | |-- runtime | | | |-- mobilenetv1 | | | |-- ... | |-- script | | |-- ...
步骤四:性能/精度评测
以MobileNet-v1模型为例,其性能评测的执行命令参考如下:
cd /userdata/ptq/script/classification/mobilenetv1
bash fps.sh # 评测帧率
bash latency.sh # 评测耗时
精度评测的执行命令参考如下:
bash accuracy.sh
脚本执行完成后,会在当前路径生成模型预测结果文件 eval.log 。请将该日志文件拷贝回开发机端OE包任意位置,
并执行以下脚本,即可得到MobileNet-v1模型的量化精度:
python3 /open_explorer/ddk/samples/ai_benchmark/xj3/ptq/tools/python_tools/accuracy_tools/cls_eval.py \
--log_file ./eval.log \
--gt_file /data/horizon_xj3/data/imagenet/val.txt
3.2.5.2.2.2. 代码结构¶
以精度评测脚本为例,其可执行程序源码的main函数定义在 code/src/simple_example.cc ,并由 workflow_accuracy.json 文件传入相关参数。
simple_example.cc的主要代码如下:
#include <fstream>
#include "plugin/input_plugin.h"
#include "plugin/output_plugin.h"
#include "plugin/workflow_plugin.h"
#include "rapidjson/document.h"
#include "rapidjson/istreamwrapper.h"
#include "rapidjson/writer.h"
#define EMPTY ""
int main(int argc, char **argv) {
// Parsing command line arguments; Init logging
...
// Parsing config
std::ifstream ifs(FLAGS_config_file);
rapidjson::IStreamWrapper isw(ifs);
rapidjson::Document document;
document.ParseStream(isw);
// Input plugin
auto input_plg = InputProducerPlugin::GetInstance();
int ret_code =
input_plg->Init(EMPTY, json_to_string(document["input_config"]));
// Workflow plugin
auto workflow_plg = WorkflowPlugin::GetInstance();
ret_code = workflow_plg->Init(EMPTY, json_to_string(document));
// Output plugin
auto output_plg = OutputConsumerPlugin::GetInstance();
ret_code = output_plg->Init(EMPTY,
json_to_string(document["output_config"]));
// Start
ret_code = input_plg->Start();
ret_code = workflow_plg->Start();
ret_code = output_plg->Start();
while (true) {
if (!input_plg->IsRunning()) { // finish
break;
}
}
// Stop
input_plg->Stop();
workflow_plg->Stop();
output_plg->Stop();
return 0;
}
其中, ai_benchmark/code/src/plugin 路径下包含了input_plg、workflow_plg、output_plg三个线程实例的类定义,
其主要作用分别是:
input_plg:用于迭代模型的输入数据。
workflow_plg:用于实现模型的前向推理和后处理。各个模型的后处理实现和统一的模型前向实现都定义在
code/src/method路径下。output_plg:用于模型推理时的性能指标统计和打印,帧id的顺序保持,精度评测时的
eval.log日志生成等。
3.2.6. 应用开发¶
当模型的性能和精度验证都符合预期后,即可参考 嵌入式应用开发指导 章节实现上层应用的具体开发。