7.4.1. 浮点模型的要求¶
7.4.1.1. symbolic_trace¶
和 PyTorch 的量化感知训练类似,horizon_plugin_pytorch 基于 fx 设计和开发,因此,要求浮点模型必须是可以正确的完成 symbolic_trace 的
7.4.1.2. 仅支持部分算子¶
由于 BPU 只支持数量有限的算子,因此,horizon_plugin_pytorch 只支持算子列表中的算子和基于 BPU 限制而内部特殊定义的特殊算子。
7.4.1.3. 构建量化友好模型¶
浮点模型变为定点模型的过程存在一定的精度误差,越是量化友好的浮点模型, qat 精度提升越容易,量化后的精度也越高。一般而言,有以下几种情况会导致模型变得量化不友好:
使用有精度风险的算子。例如: softmax , layernorm 等(详见 op 文档),这类算子一般底层由查表或多个 op 拼接实现,容易发生掉点问题。
一次 forward 中多次调用同一算子。同一算子多次调用,对应的输出分布存在差异,但只会统计一组量化参数,当多次调用的输出分布差异过大时,量化误差会变大。
add , cat 等多输入算子的不同输入差异过大,可能造成较大误差。
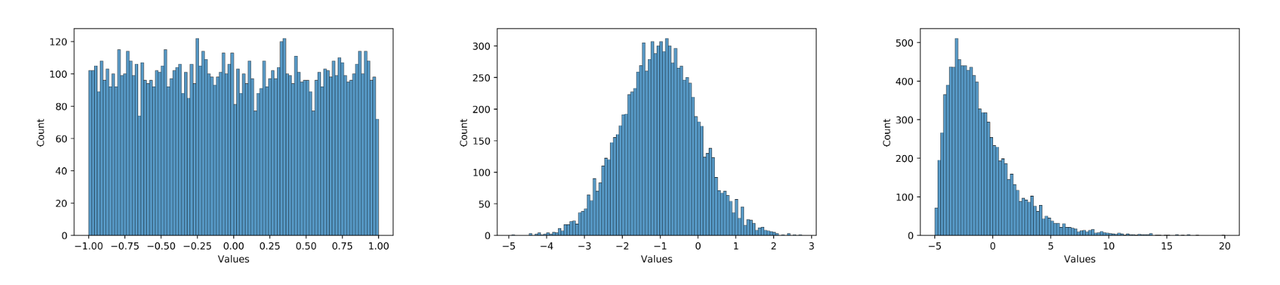
数据分布不合理。plugin 采用的是均匀对称量化,所以 0 均值的均匀分布最好,应尽量避免长尾和离群点。同时,数值范围需要与量化 bit 相匹配,如果使用int8量化分布为 [-1000, 1000] 均匀分布的数据,那么精度显然也是不够的。例如,下面三个分布图,从左到右对量化的友好性依次递减,模型中大部分数值的分布应当为中间这种分布。在实际使用中,可以用 debug 工具查看模型 weight 和 feature map 的分布是否量化友好。因为模型冗余性的存在,有些看起来分布非常量化不友好的 op 并不会显著降低模型的最终精度,需要结合实际的 qat 训练难度和最后达到的量化精度综合考虑。
那么如何使得模型更加量化友好呢?具体来说:
尽量少使用精度风险过大的算子,详见 op 文档。
保证多次调用的共享算子每次调用的输出分布差异不要太大,或者将共享算子拆开分别单独使用。
避免多输入算子不同输入的数值范围差异过大。
使用 int16 量化数值范围和误差都非常大的 op 。可通过 debug 工具找到这类 op 。
通过调大 weight decay ,增加数据增强等方式防止模型过拟合。过拟合模型容易出现较大数值,且对输入非常敏感,轻微的误差可能导致输出完全错误。
使用 BN 。
对模型输入做关于0对称的归一化。
需要注意的是, qat 自身具有一定的调整能力,量化不友好并不代表不能量化,很多情况下,即使出现上面的不适合量化的现象,仍然可以量化得很好。因为上述建议也可能会导致浮点模型精度下降,所以应当在 qat 精度无法达标时再尝试上述建议,尤其是 1 - 5 条建议,最后应当是在浮点模型精度和量化模型精度中找一个平衡点。