7.4.4. 异构模型指南¶
7.4.4.1. 异构模型介绍¶
异构模型是部署时一部分运行在 BPU 上,一部分运行在 CPU 上的模型,而非异构模型部署时则完全运行在 BPU 上。通常情况下,以下两类模型在部署时会成为异构模型:
包含 BPU 不支持算子的模型。
由于量化精度误差过大,用户指定某些算子运行在 CPU 上的模型。
7.4.4.2. 使用流程¶

通过 prepare 将浮点模型转为 QAT 模型,训练之后导出为 onnx 格式模型,由 hb_mapper 工具转为 bin 模型。
注解
用户可以通过 convert 过程得到异构定点模型,用于模型精度评测。
7.4.4.3. 算子限制¶
由于异构模型对接的是 horizon_nn,因此,其算子的支持情况和 horizon_nn 相同。
7.4.4.4. 主要接口参数说明¶
horizon_plugin_pytorch.quantization.prepare_qat_fx
设置
hybrid=True来开启异构模型功能。用户可以通过设置
hybrid_dict参数来强制指定某些 BPU 支持的算子跑在 CPU 上。
def prepare_qat_fx(
model: Union[torch.nn.Module, GraphModule],
qconfig_dict: Dict[str, Any] = None,
prepare_custom_config_dict: Dict[str, Any] = None,
optimize_graph: bool = False,
hybrid: bool = False,
hybrid_dict: Dict[str, List] = None,
) -> ObservedGraphModule:
"""Prepare QAT 模型
`model`: torch.nn.Module 或 GraphModule(使用 fuse_fx 后的模型)
`qconfig_dict`: 定义 Qconfig。如果除了 qconfig_dict 以外,还使用了 eager mode 在 module 内定义 qconfig 的方式,则 module 内定义的 qconfig 优先生效。qconfig_dict 的配置格式如下:
qconfig_dict = {
# 可选,全局配置
"": qconfig,
# 可选,按 module 类型配置
"module_type": [(torch.nn.Conv2d, qconfig), ...],
# 可选,按 module 名配置
"module_name": [("foo.bar", qconfig),...],
# 优先级:global < module_type < module_name < module.qconfig
# 非 module 类型的算子的 qconfig 默认与其父 module 的 qconfig 保持一致,如果需要单独设置,请将这部分单独封装成 module。
}
`prepare_custom_config_dict`: 自定义配置字典
prepare_custom_config_dict = {
# 暂时只支持 preserved_attributes。一般而言会自动保留所有属性,这个选项只是以防万一,几乎不会用到。
"preserved_attributes": ["preserved_attr"],
}
`optimize_graph`: 保持 cat 输入输出 scale 一致,目前只有在 Bernoulli 架构下有效。
`hybrid`: 是否使用异构模式。在以下情况下必须打开异构模式:
1. 模型包含 BPU 不支持的算子或用户希望指定部分 BPU 算子退回 CPU。
2. 用户希望 QAT 模型与 horizon_nn 对接进行定点化。
`hybrid_dict`: 定义用户主动指定的 CPU 算子。
hybrid_dict = {
# 可选,按 module 类型配置
"module_type": [torch.nn.Conv2d, ...],
# 可选,按 module 名配置
"module_name": ["foo.bar", ...],
# 优先级:module_type < module_name
# 与 qconfig_dict 类似,如果想要非 module 类型的算子运行在 CPU 上,需要将这部分单独封装成 module。
}
"""
horizon_plugin_pytorch.utils.onnx_helper.export_to_onnx
导出 onnx 模型,从而对接 hb_mapper 。
注解
该接口也支持非异构模型,其导出的 ONNX 格式模型仅用于可视化。
def export_to_onnx(
model,
args,
f,
export_params=True,
verbose=False,
training=TrainingMode.EVAL,
input_names=None,
output_names=None,
operator_export_type=OperatorExportTypes.ONNX_FALLTHROUGH,
opset_version=11,
do_constant_folding=True,
example_outputs=None,
strip_doc_string=True,
dynamic_axes=None,
keep_initializers_as_inputs=None,
custom_opsets=None,
enable_onnx_checker=False,
):
"""此接口与 torch.onnx.export 基本一致,隐藏了无需修改的参数,需要的注意参数有:
`model`: 需要 export 的模型
`args`: 模型输入,用于 trace 模型
`f`: 保存的 onnx 文件名或文件描述符
`operator_export_type`: 算子导出类型
1. 对于非异构模型,onnx 仅用于可视化,不需要保证实际可用,使用默认值 OperatorExportTypes.ONNX_FALLTHROUGH
2. 对于异构模型,onnx 需要保证实际可用,使用 None 确保导出的为标准 onnx 算子。
`opset_version`: 只能为 11,horizon_plugin_pytorch 在 opset 11 中注册了特定的映射规则。
注意:如果使用公版 torch.onnx.export,需要确保上述参数设置正确,
并且 import horizon_plugin_pytorch.utils._register_onnx_ops
以向 opset 11 中注册特定的映射规则。
"""
horizon_plugin_pytorch.quantization.convert_fx
异构模式可以复用 convert_fx 把伪量化模型转换成异构量化模型,用于评测模型精度。
注意
通过 convert_fx 得到的异构量化模型无法进行部署。目前仅用于评测模型精度。
def convert_fx(
graph_module: GraphModule,
convert_custom_config_dict: Dict[str, Any] = None,
_remove_qconfig: bool = True,
) -> QuantizedGraphModule:
"""转换 QAT 模型,仅用于评测定点模型。
`graph_module`: 经过 prepare->(calibration)->train 之后的模型
`convert_custom_config_dict`: 自定义配置字典
convert_custom_config_dict = {
# 暂时只支持 preserved_attributes。一般而言会自动保留所有属性,这个选项只是以防万一,几乎不会用到。
"preserved_attributes": ["preserved_attr"],
}
`_remove_qconfig`: convert 之后是否删除 qconfig,一般不会用到
"""
7.4.4.5. 流程和示例¶
改造浮点模型。
插入
QuantStub与DeQuantStub,保持与非异构的用法一致。如果第一个 op 是
cpu op,那么不需要插入QuantStub。如果最后一个 op 是
cpu op,那么可以不用插入DeQuantStub。
对于非
module的运算,如果需要单独设置qconfig或指定其运行在 CPU 上,需要将其封装成module,参考示例中的_SeluModule。
设置
march。设置
qconfig。保留非异构模式下在module内设置qconfig的配置方式,除此以外,还可以通过prepare_qat_fx接口的qconfig_dict参数传入qconfig,具体用法见接口参数说明。对于
BPU op,必须保证有qconfig,如果其输入 op 不为QuantStub,那么还需要保证该输入 op 有activation qconfig。对于
CPU op,qconfig不会对其产生任何影响,但如果后面接BPU op,则必须有qconfig。推荐设置方式:先设置全局
qconfig为horizon.quantization.default_qat_8bit_fake_quant_qconfig(或者horizon.quantization.default_calib_8bit_fake_quant_qconfig,根据 calibration 或 qat 阶段选择) ,在此基础上根据需求修改,一般而言,只需要对 int16 和高精度输出的 op 单独设置qconfig。
设置
hybrid_dict。可选,具体用法见接口参数说明,如果没有主动指定的 CPU 算子,可以不设置hybrid_dict。调用
prepare_qat_fx并进行calibration。参考 horizon_plugin_pytorch 开发指南章节中的 Calibration 小节内容。调用
prepare_qat_fx,加载calibration模型并进行 QAT 训练。参考 horizon_plugin_pytorch 开发指南章节中的 量化感知训练 小节内容。调用
convert_fx。可选,没有评测定点模型精度的需求时可以跳过。调用
export_to_onnx。也可以使用torch.onnx.export但需要遵守export_to_onnx接口说明中的注意事项。使用
hb_mapper转换 onnx 模型。转换后需检查算子是否运行在预期的设备上,在部分情况下,hb_mapper仍然需要设置run_on_cpu参数。比如:虽然conv在 QAT 阶段没有量化,但由于其输入(上一个算子输出)经过了伪量化,hb_mapper仍然会默认将其量化。

import copy
import numpy as np
import torch
from horizon_plugin_pytorch.march import March, set_march
from horizon_plugin_pytorch.nn import qat
from horizon_plugin_pytorch.quantization import (
prepare_qat_fx,
convert_fx,
set_fake_quantize,
FakeQuantState,
load_observer_params,
)
from horizon_plugin_pytorch.quantization.qconfig import (
default_calib_8bit_fake_quant_qconfig,
default_calib_out_8bit_fake_quant_qconfig,
default_qat_8bit_fake_quant_qconfig,
default_qat_out_8bit_fake_quant_qconfig,
)
from torch import nn
from torch.quantization import DeQuantStub, QuantStub
from horizon_plugin_pytorch.utils.onnx_helper import export_to_onnx
class _ConvBlock(nn.Module):
def __init__(self, channels=3):
super().__init__()
self.conv = nn.Conv2d(channels, channels, 1)
self.prelu = torch.nn.PReLU()
def forward(self, input):
x = self.conv(input)
x = self.prelu(x)
return torch.nn.functional.selu(x)
# 封装 functional selu 为 module,便于单独设置
class _SeluModule(nn.Module):
def forward(self, input):
return torch.nn.functional.selu(input)
class HybridModel(nn.Module):
def __init__(self, channels=3):
super().__init__()
# 插入 QuantStub
self.quant = QuantStub()
self.conv0 = nn.Conv2d(channels, channels, 1)
self.prelu = torch.nn.PReLU()
self.conv1 = _ConvBlock(channels)
self.conv2 = nn.Conv2d(channels, channels, 1)
self.conv3 = nn.Conv2d(channels, channels, 1)
self.conv4 = nn.Conv2d(channels, channels, 1)
self.selu = _SeluModule()
# 插入 DequantStub
self.dequant = DeQuantStub()
self.identity = torch.nn.Identity()
def forward(self, input):
x = self.quant(input)
x = self.conv0(x)
x = self.identity(x)
x = self.prelu(x)
x = torch.nn.functional.selu(x)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.identity(x)
x = self.conv4(x)
x = self.selu(x)
return self.dequant(x)
# 设置 march
set_march(March.XXX)
data_shape = [1, 3, 224, 224]
data = torch.rand(size=data_shape)
model = HybridModel()
qat_model = copy.deepcopy(model)
# float 模型的推理不要放在 prepare_qat_fx 之后,prepare_qat_fx 会对 float 模型做 inplace 修改
float_res = model(data)
calibration_model = prepare_qat_fx(
model,
{
"": default_calib_8bit_fake_quant_qconfig,
# selu 为 cpu 算子,conv4 实际上是 bpu 模型的输出,设置为高精度输出
"module_name": [("conv4", default_calib_out_8bit_fake_quant_qconfig)]
},
hybrid=True,
hybrid_dict={
"module_name": ["conv1.conv", "conv3"],
"module_type": [_SeluModule],
},
)
# calibration 阶段需确保原有模型不会发生变化
calibration_model.eval()
set_fake_quantize(calibration_model, FakeQuantState.CALIBRATION)
for i in range(5):
calibration_model(torch.rand(size=data_shape))
qat_model = prepare_qat_fx(
qat_model,
{
"": default_qat_8bit_fake_quant_qconfig,
# selu 为 cpu 算子,conv4 实际上是 bpu 模型的输出,设置为高精度输出
"module_name": [("conv4", default_qat_out_8bit_fake_quant_qconfig)]
},
hybrid=True,
hybrid_dict={
"module_name": ["conv1.conv", "conv3"],
"module_type": [_SeluModule],
},
)
load_observer_params(calibration_model, qat_model)
set_fake_quantize(calibration_model, FakeQuantState.QAT)
# qat training start
# ......
# qat training end
# 导出 qat.onnx
export_to_onnx(
qat_model,
data,
"qat.onnx",
operator_export_type=None,
)
# 评测定点模型
quantize_model = convert_fx(qat_model)
quantize_res = quantize_model(data)
打印 QAT 模型的结果。
HybridModel(
(quant): QuantStub(
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_tensor_symmetric, ch_axis=-1, scale=tensor([0.0078]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([-0.9995]), max_val=tensor([0.9995]))
)
)
(conv0): Conv2d(
3, 3, kernel_size=(1, 1), stride=(1, 1)
(weight_fake_quant): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_channel_symmetric, ch_axis=0, scale=tensor([0.0038, 0.0041, 0.0016]), zero_point=tensor([0, 0, 0])
(activation_post_process): MovingAveragePerChannelMinMaxObserver(min_val=tensor([-0.4881, -0.4944, 0.0787]), max_val=tensor([-0.1213, 0.5284, 0.1981]))
)
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_tensor_symmetric, ch_axis=-1, scale=tensor([0.0064]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([-0.8159]), max_val=tensor([0.8159]))
)
)
(prelu): PReLU(num_parameters=1)
(conv1): _ConvBlock(
(conv): Conv2d(3, 3, kernel_size=(1, 1), stride=(1, 1))
(prelu): PReLU(num_parameters=1)
)
(conv2): Conv2d(
3, 3, kernel_size=(1, 1), stride=(1, 1)
(weight_fake_quant): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_channel_symmetric, ch_axis=0, scale=tensor([0.0040, 0.0044, 0.0040]), zero_point=tensor([0, 0, 0])
(activation_post_process): MovingAveragePerChannelMinMaxObserver(min_val=tensor([-0.5044, -0.4553, -0.5157]), max_val=tensor([0.1172, 0.5595, 0.4104]))
)
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_tensor_symmetric, ch_axis=-1, scale=tensor([0.0059]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([-0.7511]), max_val=tensor([0.7511]))
)
)
(conv3): Conv2d(3, 3, kernel_size=(1, 1), stride=(1, 1))
(conv4): Conv2d(
3, 3, kernel_size=(1, 1), stride=(1, 1)
(weight_fake_quant): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_channel_symmetric, ch_axis=0, scale=tensor([0.0025, 0.0037, 0.0029]), zero_point=tensor([0, 0, 0])
(activation_post_process): MovingAveragePerChannelMinMaxObserver(min_val=tensor([-0.2484, -0.4718, -0.3689]), max_val=tensor([ 0.3239, -0.0056, 0.3312]))
)
(activation_post_process): None
)
(selu): _SeluModule()
(dequant): DeQuantStub()
(identity): Identity()
(prelu_input_dequant): DeQuantStub()
(selu_1_activation_post_process): _WrappedCalibFakeQuantize(
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_tensor_symmetric, ch_axis=-1, scale=tensor([0.0042]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([-0.5301]), max_val=tensor([0.5301]))
)
)
(conv3_activation_post_process): _WrappedCalibFakeQuantize(
(activation_post_process): FakeQuantize(
fake_quant_enabled=tensor([1], dtype=torch.uint8), observer_enabled=tensor([1], dtype=torch.uint8), quant_min=-128, quant_max=127, dtype=qint8, qscheme=torch.per_tensor_symmetric, ch_axis=-1, scale=tensor([0.0072]), zero_point=tensor([0])
(activation_post_process): MovingAverageMinMaxObserver(min_val=tensor([-0.9156]), max_val=tensor([0.9156]))
)
)
(conv3_input_dequant): DeQuantStub()
(selu_2_input_dequant): DeQuantStub()
)
def forward(self, input):
input_1 = input
quant = self.quant(input_1); input_1 = None
conv0 = self.conv0(quant); quant = None
identity = self.identity(conv0); conv0 = None
prelu_input_dequant_0 = self.prelu_input_dequant(identity); identity = None
prelu = self.prelu(prelu_input_dequant_0); prelu_input_dequant_0 = None
selu = torch.nn.functional.selu(prelu, inplace = False); prelu = None
conv1_conv = self.conv1.conv(selu); selu = None
conv1_prelu = self.conv1.prelu(conv1_conv); conv1_conv = None
selu_1 = torch.nn.functional.selu(conv1_prelu, inplace = False); conv1_prelu = None
selu_1_activation_post_process = self.selu_1_activation_post_process(selu_1); selu_1 = None
conv2 = self.conv2(selu_1_activation_post_process); selu_1_activation_post_process = None
conv3_input_dequant_0 = self.conv3_input_dequant(conv2); conv2 = None
conv3 = self.conv3(conv3_input_dequant_0); conv3_input_dequant_0 = None
conv3_activation_post_process = self.conv3_activation_post_process(conv3); conv3 = None
identity_1 = self.identity(conv3_activation_post_process); conv3_activation_post_process = None
conv4 = self.conv4(identity_1); identity_1 = None
selu_2_input_dequant_0 = self.selu_2_input_dequant(conv4); conv4 = None
selu_2 = torch.nn.functional.selu(selu_2_input_dequant_0, inplace = False); selu_2_input_dequant_0 = None
dequant = self.dequant(selu_2); selu_2 = None
return dequant
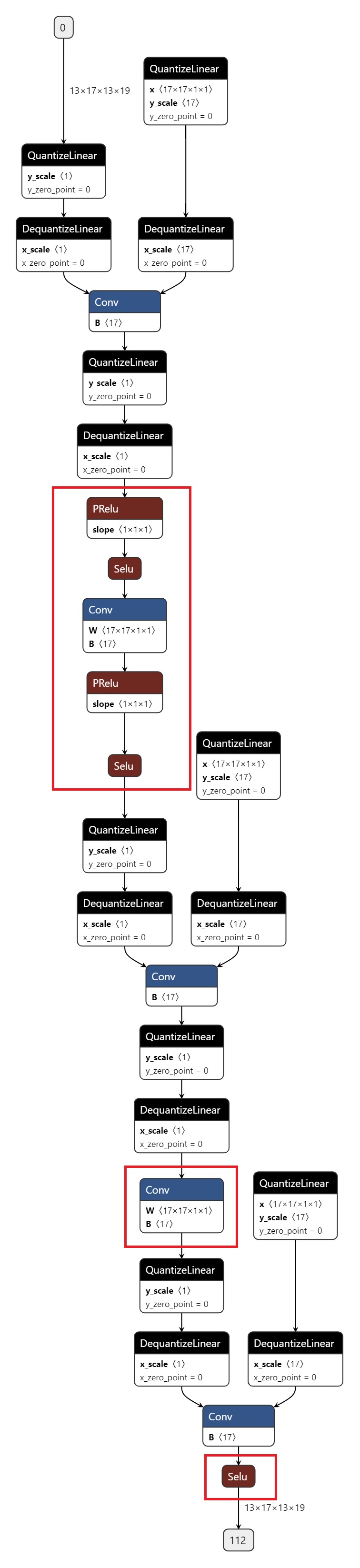
导出的 onnx 如图所示,红色圈出部分为 CPU 算子。